
使用Hive的窗口函数进行数据分析——以股票市场分析为例
声明:本文主要是实现利用Hive常用的窗口函数和一些数据分析思维分析数据,只是套用在股票数据的例子上,因此并不适用于提高投资技巧!我们先看一下常用Hive中常用的窗口:PRECEDING:往前FOLLOWING:往后CURRENT ROW:当前行UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用)UNBOUNDED PRECEDING 表示该窗口最前面的行(起...
声明:本文主要是实现利用Hive常用的窗口函数和一些数据分析思维分析数据,只是套用在股票数据的例子上,因此并不适用于提高投资技巧!
我们先看一下常用Hive中常用的窗口:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用)
UNBOUNDED PRECEDING 表示该窗口最前面的行(起点)
UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)
接下来我们将会使用Hive的窗口函数分析股票数据
1.观察数据
假设我们有两个市场,分别是代表中国蓝筹股的沪深300指数,一个是美国的标普500指数。数据时通过每天记录下来的,具体我们使用18年3月的数据(为了计算收益率,我们前后延长一天,即18年2月28日到18年4月1日),如下图:
use dmb_dev;
drop table if exists dmb_dev.market_index_data_dayily;
CREATE TABLE dmb_dev.market_index_data_dayily
(
market string comment '股票市场',
trade_date string comment '交易日期',
index_value double comment '价格'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
set hive.cli.print.header=true;
set hive.resultset.use.unique.column.names=false;
use dmb_dev;
load data local inpath 'index_data.csv' into table dmb_dev.market_index_data_dayily;
select * from dmb_dev.market_index_data_dayily limit 10;
可以看到数据时按照时间排列,由于沪深300和标普500在2018年2月的起点不同通,因此直接比较指数的值是没有意义的。
1.LEAD(),LAG()计算收益率
先看两个函数
- .LEAD(col,n,DEFAULT)
用于统计窗口内往下第n行值第一个参数为列名,第二个参数为往下第n行(可选,默认为1,不可为负数),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL) - LAG(col,n,DEFAULT)
用于统计窗口内往上第n行值第一个参数为列名,第二个参数为往上第n行(可选,默认为1,不可为负数),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
select *
, lead(index_value,1,-999) over (partition by market order by trade_date) as lead_1_value
, lag(index_value,1,-999) over (partition by market order by trade_date) as lag_1_value
from market_index_data_dayily;
部分结果如下: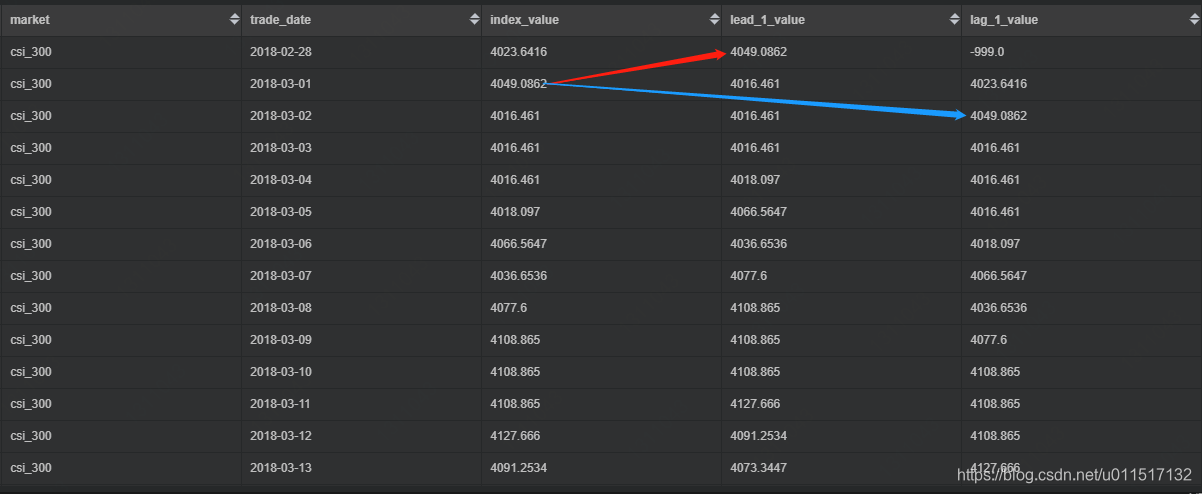
看到lead_1_value是后一行的index_value,lag_1_value 是前一行的index_value。
LEAD和LAG在这里有什么用呢,我们可以利用LEAD或LAG计算收益率。这里我们使用LAG计算收益率,收益率计算公式采用对数收益率:r=ln(pt/pt−1)r = ln(p_t/p_{t-1})r=ln(pt/pt−1),使用对数收益率的好处是满足可加性。
use dmb_dev;
drop table if exists dmb_dev.market_index_profit_dayily;
create table dmb_dev.market_index_profit_dayily as
select *
, round(log(index_value/lag(index_value,1,-999) over (partition by market order by treade_date)), 4) as profit_rate --计算对数收益率
from market_index_data_dayily
;
select * from market_index_profit_dayily;
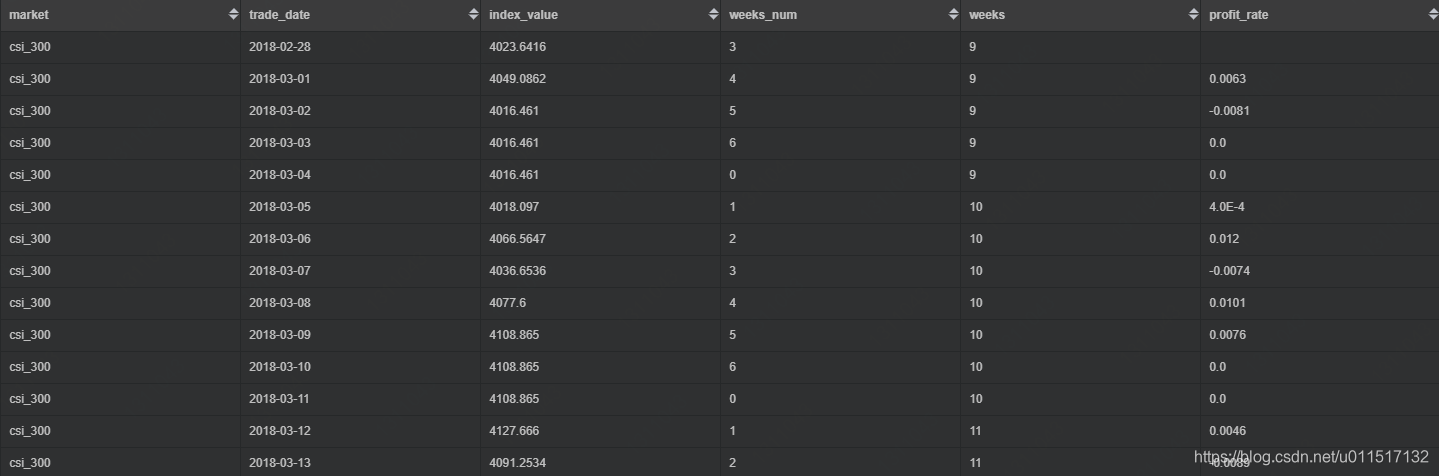
可以看到profit_rate即是我们计算出的对数收益率,我们同时计算了trade_date所在的周数和星期几(0代表周天),后面会用到。
2.FIRST_VALUE(),LAST_VALUE()查看排名最早最晚观测值
- FIRST_VALUE
取分组内排序后,截止到当前行,第一个值,这最多需要两个参数。第一个参数是您想要第一个值的列,第二个(可选)参数必须是false默认为布尔值的布尔值。如果设置为true,则跳过空值。 - LAST_VALUE
取分组内排序后,截止到当前行,最后一个值,这最多需要两个参数。第一个参数是您想要第一个值的列,第二个(可选)参数必须是false默认为布尔值的布尔值。如果设置为true,则跳过空值。
我们可以查看截止到每个trade_date的第一个收益率和最后一个收益率:
select *
--表示从起点到当前行
,first_value(profit_rate) over (partition by market order by trade_date rows between unbounded preceding and current row) as first_value_pr
,last_value(profit_rate) over (partition by market order by trade_date rows between unbounded preceding and current row) as last_value_pr
from market_index_profit_dayily
--除去周六周天
where trade_date>='2018-03-01' and trade_date<='2018-03-31' and weeks_num not in (0,6);
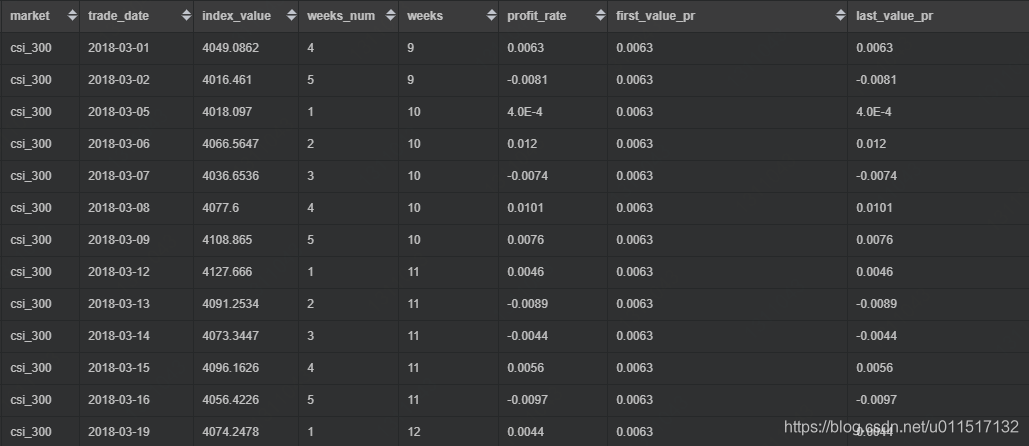
我们还可以加入window子句,使用自己想使用的窗口长度,来观察数据:
select *
--不限制窗口
,first_value(profit_rate) over (partition by market order by trade_date) as first_value_pr
--表示从起点到当前行
,first_value(profit_rate) over (partition by market order by trade_date rows between unbounded preceding and current row) as window_first_value_pr
,last_value(profit_rate) over (partition by market order by trade_date) as last_value_pr
--表示起点到终点
,last_value(profit_rate) over (partition by market order by trade_date rows between unbounded preceding and unbounded following) as window_last_value_pr
--前后两天窗口
,first_value(profit_rate) over (partition by market order by trade_date rows between 2 preceding AND 3 following) as window_2_first_value_pr
,last_value(profit_rate) over (partition by market order by trade_date rows between 2 preceding AND 3 following) as window_2_last_value_pr
from market_index_profit_dayily
--除去周六周天
where trade_date>='2018-03-01' and trade_date<='2018-03-31' and weeks_num not in (0,6);
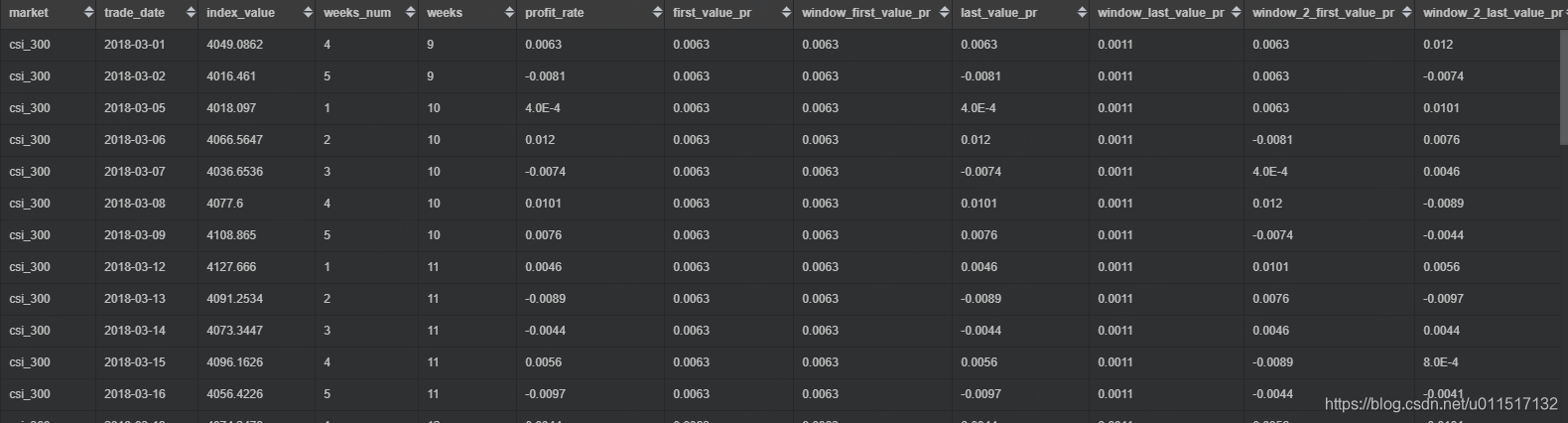
查询结果如上图
3.SUM(),MAX(),MIN(),AVG()计算股票窗口内累计收益率等指标
实际上,大部分的数学计算相关的聚合函数,大多都能套用在窗口函数中。
此处我们使用SUM()举例,计算每种指数在当月和每周,以及指定窗口的的累积收益率,对数收益率可以直接sum计算累积收益率。通过累计收益率、平均收益率、最小收益率(一定程度代表风险)来研究资产的走势和特点
select *
--每种之中在当月的累计收益率
,SUM(profit_rate) over (partition by market order by trade_date) as sum_month_pr_1
--每种之中在每周的累计收益率
,SUM(profit_rate) over (partition by market, weeks order by trade_date) as sum_week_pr_1
--表示从起点到当前行,与sum_month_pr_1结果一致
,SUM(profit_rate) over (partition by market order by trade_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as sum_pr_2
--表示窗口内所有行,和直接sum() groupby 效果一样
,SUM(profit_rate) over (partition by market) as sum_pr_3
--表示起点到终点,和直接sum() groupby 效果一样
,SUM(profit_rate) over (partition by market order by trade_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as sum_pr_4
----表示前2行到后面3行的窗口的累积收益率
,SUM(profit_rate) over (partition by market order by trade_date ROWS BETWEEN 2 PRECEDING AND 3 FOLLOWING) as sum_pv_5
from market_index_profit_dayily
--除去周六周天
where trade_date>='2018-03-01' and trade_date<='2018-03-31' and weeks_num not in (0,6)
order by market, trade_date;
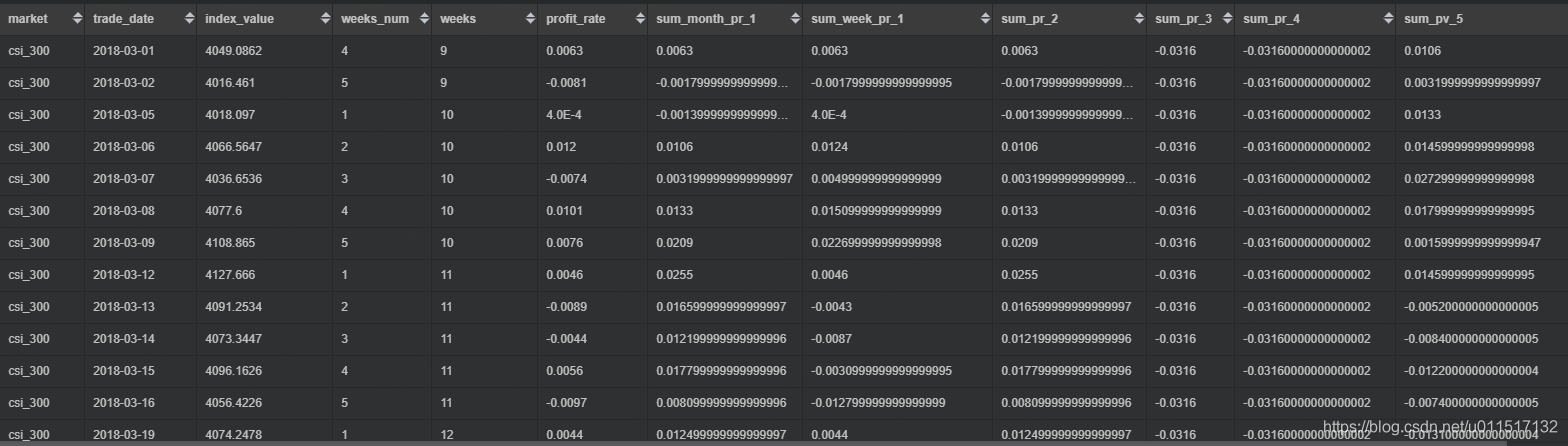
4.ROW_NUMBER(),RANK(),DENSE_RANK()对窗口内数据进行排序
.ROW_NUMBER
从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列;通常用于获取分组内排序第一的记录;获取一个session中的第一条refer等。
2.RANK
生成数据项在分组中的排名,排名相等会在名次中留下空位。产生类似1、1、3的排名
3.DENSE_RANK
生成数据项在分组中的排名,排名相等会在名次中不会留下空位。产生类似1、1、2的排名
我们可以计算股票在窗口期内的排名情况(在实际分析中,其实没太大用,我们更关心股票的趋势,而不是收益率在每天的排名)
select *
--当月每种资产的净值排名
,ROW_NUMBER() over (partition by market order by index_value) as row_number_month_pv_1
--每周每种资产的净值排名
,RANK() over (partition by market, weeks order by index_value) as row_number_week_pv_2
--当月每种资产的净值排名,会留空位
,RANK() over (partition by market order by index_value) as row_number_pv_2
--当月每种资产的净值排名,不会留空位
,DENSE_RANK() over (partition by market order by index_value) as row_number_pv_3
from market_index_profit_dayily
where trade_date>='2018-03-01' and trade_date<='2018-03-31' ;
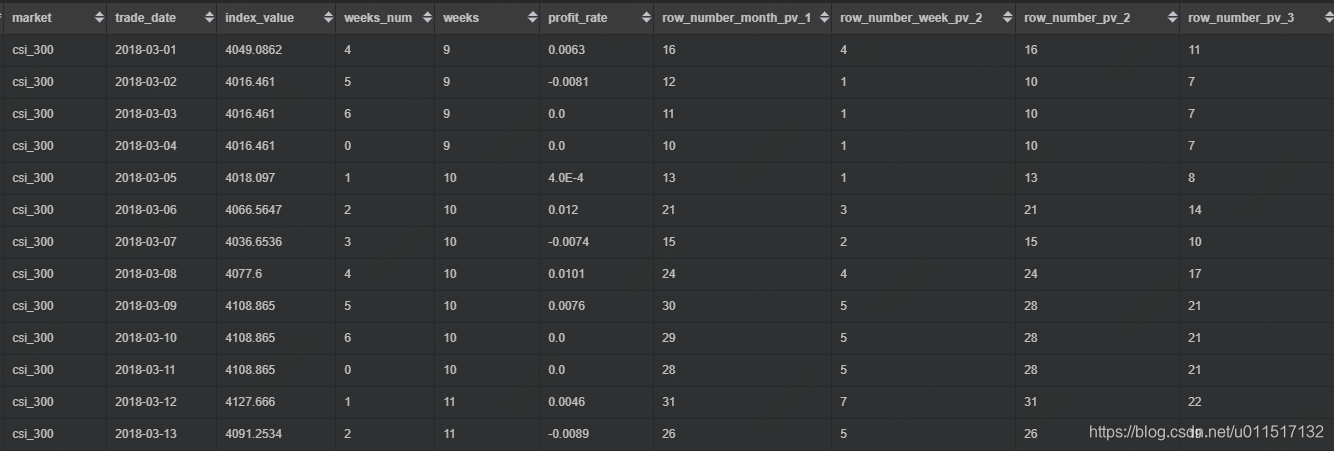
光靠窗口函数分析股票净值数据肯定是不够的,我们还需要进一步分析收益、风险、风险调整收益和其他环境因素才能对一只股票有一定的了解。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)