
Python Selenium自动化网页数据抓取实践
本文还有配套的精品资源,点击获取简介:Selenium是一个强大的Web自动化测试工具,能够模拟用户行为进行网页交互。本项目“selenium_scraper”将展示如何利用Python的Selenium库进行网页数据抓取。项目包含源代码文件、配置文件、测试文件、依赖项、日志文件和数据存储等,涉及元素定位、交互操作、等待策略、JavaScript处理和异常处理等关键概念。...

简介:Selenium是一个强大的Web自动化测试工具,能够模拟用户行为进行网页交互。本项目“selenium_scraper”将展示如何利用Python的Selenium库进行网页数据抓取。项目包含源代码文件、配置文件、测试文件、依赖项、日志文件和数据存储等,涉及元素定位、交互操作、等待策略、JavaScript处理和异常处理等关键概念。开发者通过此项目可深入掌握复杂网页抓取技能,并结合requests和BeautifulSoup等库,打造高效灵活的数据抓取方案。 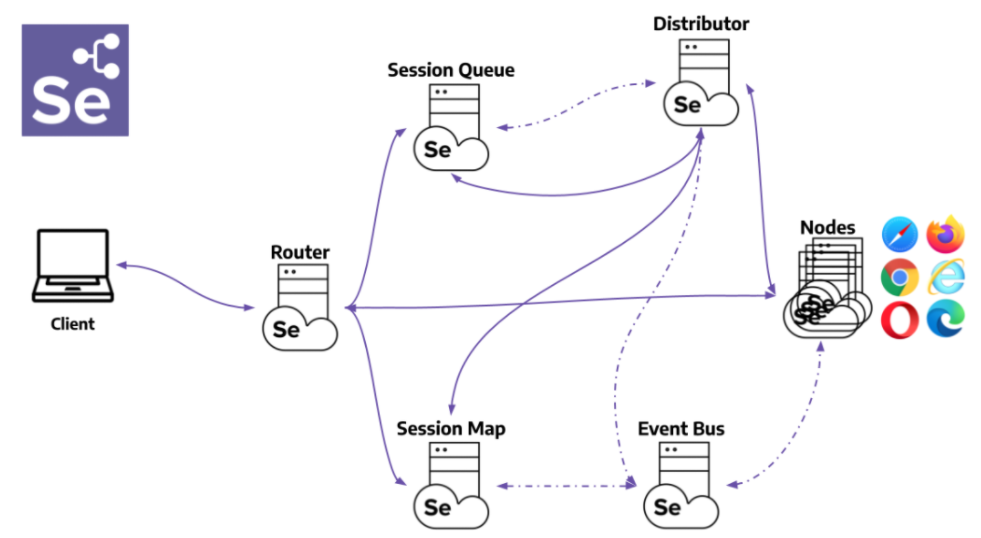
1. Selenium自动化测试工具介绍
1.1 Selenium的历史与重要性
Selenium 是一个用于Web应用程序测试的工具。它最初由Jason Huggins于2004年开发,目的是为了自动化浏览器操作,以验证Web应用的各个功能是否按预期工作。由于其强大的功能和灵活性,Selenium迅速成为自动化测试领域的领先工具之一。它支持多种浏览器,如Chrome、Firefox、Internet Explorer等,并且能够与多种编程语言配合使用,包括但不限于Python、Java、C#等。
1.2 Selenium的主要功能和用途
Selenium的主要功能包括但不限于: - 浏览器自动化 :Selenium允许测试人员模拟用户的各种浏览器操作,如点击、输入、导航等。 - 跨平台测试 :可以在多个操作系统和浏览器上执行测试,确保应用的跨平台兼容性。 - 集成与扩展 :可以很容易地与持续集成系统(如Jenkins)、测试管理工具(如JIRA)以及其他测试工具集成。 - 动态内容测试 :Selenium可以处理JavaScript生成的内容和Ajax调用,这对于现代Web应用是必不可少的。
Selenium广泛应用于回归测试、功能测试、负载测试和接受测试中,极大地提高了测试效率,缩短了产品上市时间。它被认为是测试人员必备的工具之一,尤其是在敏捷开发环境中,其重要性不言而喻。
2. Python网页抓取实战
2.1 Python基础回顾
Python语言的简洁和强大为网页抓取提供了便利。在深入探讨使用Python进行网页抓取之前,让我们先快速回顾一下Python的基础知识,为后续的实战应用打下坚实的基础。
2.1.1 Python环境搭建
对于Python初学者,首先需要安装Python环境。推荐使用Python 3.x版本,并且需要选择适合操作系统的安装包进行安装。通常,安装过程中会包括 pip 包管理工具,用于安装各种Python库。以下是Windows系统下搭建Python环境的步骤:
- 下载Python安装包。
- 运行安装程序,确保勾选
Add Python to PATH,以便在命令行中直接使用Python。 - 安装完成后,打开命令提示符,输入
python --version,如果显示出Python的版本号,则环境搭建成功。
2.1.2 Python基础语法
掌握一些基础的Python语法是进行网页抓取的前提条件。在Python中,一切皆为对象,函数和模块也是对象。以下是一些基础语法点:
-
变量和数据类型 :Python中的变量不需要声明类型,可直接赋值。常见数据类型包括整型、浮点型、字符串、列表、字典等。
python number = 10 # 整型 pi = 3.1415 # 浮点型 greeting = "Hello" # 字符串 -
控制流程 :使用
if、elif和else进行条件判断,使用for和while进行循环。
python if number > 5: print("Number is greater than 5") else: print("Number is less than or equal to 5")
- 函数 :定义函数使用
def关键字,函数可以有参数,也可以返回值。
python def add(a, b): return a + b
- 模块和包 :可以使用
import关键字导入模块,模块可以组织成包。
```python import math import datetime
current_time = datetime.datetime.now() ```
本节只覆盖了Python的一些基础知识点,但在实际的网页抓取项目中,我们可能会用到更多高级特性,例如正则表达式、异常处理等。因此,建议读者根据实际需求进一步深入学习Python语言。
2.2 Selenium自动化测试框架
Selenium是一个用于Web应用程序测试的工具,它让浏览器自动化测试变得简单。它支持多种浏览器,如Chrome、Firefox、Internet Explorer等,并且可以运行在不同的操作系统上。
2.2.1 Selenium工作原理
Selenium通过一个叫做WebDriver的API与浏览器进行交互。WebDriver提供了一套丰富的接口,用于模拟用户的操作行为,比如点击、输入、导航等。这些接口可以控制浏览器的行为,使得自动化测试或者网页抓取成为可能。
Selenium工作流程大致如下: 1. 用户编写测试脚本,脚本中包含了一系列的操作指令。 2. WebDriver接收这些指令,调用浏览器内置的JavaScript代码或者其他机制来模拟用户操作。 3. 浏览器执行相应的动作,并将结果返回给WebDriver。 4. WebDriver将执行结果反馈给用户,完成测试或抓取任务。
2.2.2 Selenium与浏览器驱动
要使Selenium正常工作,浏览器驱动是不可或缺的一部分。浏览器驱动充当了WebDriver与浏览器之间的桥梁。每种浏览器通常都有自己的驱动程序,例如: - Chrome浏览器使用ChromeDriver。 - Firefox浏览器使用GeckoDriver。
安装驱动程序通常需要下载对应浏览器版本的驱动,并将其路径添加到系统的环境变量中。这样,Selenium才能正确地找到并使用这些驱动程序。
在Python中,你可以使用 pip 安装Selenium库:
pip install selenium
安装好Selenium库后,我们可以开始编写简单的爬虫程序,进行网页元素定位与信息提取。接下来的章节,将详细介绍如何实现这些操作。
3. WebDriver使用与浏览器控制
3.1 WebDriver的安装与配置
3.1.1 不同浏览器驱动的选择
当在使用Selenium进行自动化测试时,选择合适的浏览器驱动是至关重要的一步。在众多浏览器驱动中,最常用的是ChromeDriver、GeckoDriver和Internet Explorer Driver Server。
- ChromeDriver 是专门为谷歌浏览器Chrome设计的驱动程序,它支持最新版本的Chrome浏览器,并且与Selenium有着良好的兼容性。对于大多数开发者和测试工程师来说,由于Chrome浏览器的普及,ChromeDriver是首选。
- GeckoDriver 是为Mozilla Firefox浏览器提供的驱动。它与较新的Firefox版本兼容,并且通过WebDriver API为Selenium提供接口。由于Firefox浏览器对一些Web技术的支持更全面,对于需要测试这些特性的场景,GeckoDriver提供了良好的支持。
- Internet Explorer Driver Server (IEDriverServer) 是针对旧版IE浏览器开发的驱动程序。随着现代浏览器的流行,IE驱动的需求正在逐步减少。尽管如此,由于某些旧系统和遗留应用可能仍然依赖于IE,因此在特定情况下,IEDriverServer仍然是必需的。
选择驱动时,还需考虑驱动程序的版本与浏览器版本的兼容性问题。建议总是下载与浏览器版本相匹配的最新稳定版本的驱动程序。此外,还应当注意在操作系统层面配置好驱动程序的路径,以便Selenium能够在代码中正确调用。
3.1.2 WebDriver与浏览器交互原理
WebDriver是Selenium的核心组件之一,它是一个用于自动化浏览器操作的API。它能够让开发者通过编程语言来控制浏览器行为,执行打开网页、点击按钮、填写表单等各种操作。这一切都是通过浏览器驱动程序与浏览器内核进行交互来实现的。
工作原理:
- 初始化 WebDriver 实例 :首先在代码中创建一个WebDriver的实例,这将启动一个浏览器窗口。WebDriver会与操作系统的网络栈进行通信,向对应的浏览器驱动发送HTTP请求。
-
与浏览器驱动交互 :当WebDriver发出执行操作的指令时,如打开一个网页,浏览器驱动接收到这些指令后,通过浏览器的插件接口或扩展机制,执行相应的操作。
-
完成操作并反馈结果 :浏览器执行完操作后,驱动会将结果以特定的格式返回给WebDriver,然后WebDriver将这些结果返回给测试脚本。测试脚本得到这些结果后,就可以进行下一步的判断或操作。
WebDriver的这个工作流程,使得自动化测试能够非常接近于真实用户的操作。由于其背后的浏览器驱动程序通常由浏览器官方或社区维护,因此它能够较好地适应浏览器版本更新带来的变化。
3.2 浏览器控制技巧
3.2.1 浏览器窗口管理
在自动化测试过程中,经常需要对浏览器窗口进行各种操作,例如打开新窗口、切换窗口、调整窗口大小等。WebDriver提供了丰富的API来实现这些窗口管理功能。
窗口切换 :
from selenium import webdriver
# 打开浏览器
driver = webdriver.Chrome()
# 打开新窗口
driver.execute_script("window.open('');")
# 获取当前所有窗口句柄
windows = driver.window_handles
# 切换到第一个窗口
driver.switch_to.window(windows[0])
以上代码展示了如何打开一个新窗口以及如何在多个窗口间切换。 window_handles 属性会返回一个包含所有打开窗口句柄的列表,通过 switch_to.window() 方法可以切换到指定窗口。
窗口大小调整 :
# 设置窗口大小
driver.set_window_size(1200, 800)
set_window_size() 方法允许指定窗口的新宽度和高度。调整窗口大小有助于测试不同分辨率下的网页布局。
3.2.2 浏览器标签页操作
标签页作为浏览器的一个重要组成部分,管理好标签页的打开和切换对于自动化测试也是十分必要的。
标签页打开 :
# 打开新标签页
driver.execute_script("window.open('');")
这与打开新窗口的操作类似,但新标签页将保持在当前窗口中。
标签页切换 :
# 获取所有标签页句柄
tabs = driver.window_handles
# 切换到最后一个标签页
driver.switch_to.window(tabs[-1])
切换标签页时,同样使用 switch_to.window() 方法,但需要传入对应标签页的句柄。
以上操作对于模拟用户在多个标签页间进行浏览的行为十分有用,是Web自动化测试中不可或缺的部分。
3.3 模拟用户行为
3.3.1 模拟键盘和鼠标事件
用户与Web应用交互的最常见方式是使用键盘和鼠标。为了实现模拟真实用户行为的自动化测试,Selenium提供了模拟键盘和鼠标事件的能力。
键盘事件 :
``` mon.keys import Keys
找到输入框并输入文本
input_element = driver.find_element_by_id("input_id") input_element.send_keys("Hello World!")
模拟按下回车键
input_element.send_keys(Keys.RETURN)
`Keys`类定义了许多键盘事件,如回车键(RETURN)、空格键(SPACE)、退格键(BACKSPACE)等,可以用`send_keys()`方法模拟。
**鼠标事件**:
```***
***mon.action_chains import ActionChains
# 移动到指定元素上并点击
element = driver.find_element_by_id("element_id")
ActionChains(driver).move_to_element(element).click().perform()
ActionChains 类用于模拟用户的鼠标操作,如点击、双击、右键点击、鼠标悬停等。
3.3.2 模拟表单填写与提交
对于测试表单功能的场景,模拟用户填写表单信息并提交是一个常见需求。通过Selenium,可以很轻松地实现这一系列操作。
# 找到表单的各个输入元素
name_input = driver.find_element_by_id("name")
email_input = driver.find_element_by_id("email")
submit_button = driver.find_element_by_id("submit")
# 填写表单并提交
name_input.send_keys("John Doe")
email_input.send_keys("john.***")
submit_button.click()
以上代码段演示了如何顺序填写姓名和电子邮件地址,并提交表单。这一过程模拟了用户的真实操作,有助于确保Web应用中的表单功能按预期工作。
模拟用户行为的自动化测试可以提高测试的效率和覆盖度,有助于发现那些可能在常规测试中被忽视的问题。通过本章节的介绍,我们了解了如何通过Selenium实现浏览器控制和用户行为模拟,为编写高效且全面的自动化测试脚本提供了坚实的基础。
4. Selenium核心组件与元素定位策略
4.1 Selenium核心组件解析
4.1.1 WebDriver对象
WebDriver对象是Selenium自动化测试框架中用于与浏览器驱动程序进行通信的接口。它允许开发者模拟用户与网页之间的各种交互行为。在Python中,WebDriver对象通常是通过浏览器驱动程序的类实例化来创建的。
from selenium import webdriver
# 创建一个Chrome WebDriver实例
driver = webdriver.Chrome()
在上述代码中,实例化了一个Chrome WebDriver对象。这意味着我们已经准备好了与Chrome浏览器进行交云的工具。
4.1.2 WebElement对象
WebElement是Selenium中用于表示网页上单个元素的接口。通过该接口,我们可以获取或操作页面上的元素,如输入文本、点击按钮等。WebElement对象通常通过WebDriver对象的find_element方法获得。
element = driver.find_element_by_id("element-id")
在上述代码中, find_element_by_id 方法返回了一个WebElement对象,代表了页面上id为"element-id"的元素。
4.1.3 WebDriver和WebElement之间的关系
WebDriver对象可以看作是管理者,负责打开浏览器、导航到网页、控制浏览器窗口等。而WebElement对象则是具体的执行者,负责与页面上的具体元素进行交互。
4.2 元素定位方法
4.2.1 ID、Name定位
ID和Name定位是两种非常直接且常用的元素定位方式。在HTML中,每个元素都有一个唯一的ID,也可能会有一个Name属性。使用Selenium时,可以利用这些属性快速定位到元素。
# 通过ID定位元素
element_by_id = driver.find_element_by_id("element-id")
# 通过Name定位元素
element_by_name = driver.find_element_by_name("element-name")
这两种方法通常用于那些唯一标识的元素,如输入框、按钮等。
4.2.2 CSS选择器与XPath定位
CSS选择器和XPath是两种更为灵活和强大的定位方法。它们可以在元素的属性、类、标签名等多方面进行定位,特别适用于复杂页面结构的元素定位。
# 通过CSS选择器定位元素
element_by_css = driver.find_element_by_css_selector("div#element-id.class-name")
# 通过XPath定位元素
element_by_xpath = driver.find_element_by_xpath("//div[@id='element-id' and contains(@class, 'class-name')]")
使用CSS选择器和XPath定位可以提供更为精确和复杂的选择能力。不过,这些定位方法也较为复杂,需要一定的学习和实践才能熟练运用。
4.3 定位策略优化
4.3.1 定位策略对比分析
在进行自动化测试或网页抓取时,选择合适的元素定位策略非常关键。ID和Name定位方法简单易用,但不适用于属性经常变动的动态网页。而CSS选择器和XPath提供了更高的灵活性和准确性,但相应的编写难度和维护成本也会增加。
下表展示了不同定位方法的特点和适用场景:
| 定位方法 | 特点 | 适用场景 | | --- | --- | --- | | ID定位 | 简单快速,定位唯一 | 页面结构简单,元素ID唯一且稳定 | | Name定位 | 适用于输入框、按钮等 | 输入框、单选按钮、复选框等表单元素 | | CSS选择器 | 灵活,功能强大 | 复杂页面结构,需要根据多个属性定位元素 | | XPath | 功能最为强大,定位准确 | 需要精确选择元素时,如动态内容,嵌套结构 |
4.3.2 隐式等待与显式等待的运用
在进行页面元素操作时,经常会遇到元素未及时加载完成的情况,这就需要使用等待策略。Selenium提供了隐式等待和显式等待两种策略来处理元素的加载问题。
# 隐式等待
driver.implicitly_wait(10) # 10秒内元素加载出来则继续,否则抛出TimeoutException
# 显式等待
***mon.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
element = wait.until(EC.presence_of_element_located((By.ID, "element-id")))
隐式等待为所有元素的查找操作设置了一个固定时间的等待期,而显式等待则允许你对特定条件进行等待,直到满足条件后再继续执行。显式等待通常更为灵活和强大,因为它可以根据实际情况来设定等待条件。
5. 网页交互操作与等待策略
5.1 网页交互操作
在自动化测试和网页数据抓取的过程中,与网页元素进行交互是核心步骤之一。这涉及到多种元素,例如框架、内嵌窗口、下拉菜单以及弹窗等。理解并掌握如何高效地处理这些交互能够显著提高测试或抓取任务的效率和准确性。
5.1.1 框架和内嵌窗口操作
一个网页可能会包含多个iframe框架或内嵌窗口,这些框架内部可能有独立的文档和事件流。为了在Selenium中定位和操作这些框架内的元素,首先需要切换到相应的iframe。
``` mon.by import By
driver = webdriver.Chrome() driver.get("***")
切换到iframe
frame = driver.find_element(By.ID, "frameid") driver.switch_to.frame(frame)
现在可以定位框架内的元素了
element = driver.find_element(By.ID, "elementid")
完成后切回主文档
driver.switch_to.default_content()
在上述代码中,`driver.switch_to.frame()` 方法用于切换到指定的iframe,之后就可以操作该iframe内的元素了。完成操作后,`driver.switch_to.default_content()` 方法可以用来切换回主文档内容。
### 5.1.2 下拉菜单和弹窗处理
处理下拉菜单或弹窗的交互操作也非常重要,尤其是当网页中的交互元素影响到自动化脚本的执行流程时。Selenium提供了一些非常实用的方法来操作这些元素。
```python
from selenium.webdriver.support.ui import Select
# 假设有一个下拉菜单,其元素ID是'dropdown'
select_element = driver.find_element(By.ID, 'dropdown')
# 使用Select类操作下拉菜单
select = Select(select_element)
select.select_by_visible_text('选项2') # 选择可见文为'选项2'的选项
# 处理弹窗
try:
alert = driver.switch_to.alert
alert.accept() # 点击弹窗的“确认”按钮
except NoAlertPresentException:
print("没有弹窗出现")
在这个例子中, Select 类用于操作下拉菜单, switch_to.alert 方法用于处理弹窗。使用 try-except 结构可以妥善处理可能没有出现的弹窗。
5.2 等待策略应用
在网页操作自动化过程中,等待策略是重要的组成部分,因为网络延迟和动态内容加载等因素可能导致元素还未就绪。Selenium提供了几种等待策略,包括强制等待、隐式等待和显式等待。
5.2.1 强制等待与隐式等待
强制等待和隐式等待是两种简单的等待方式。强制等待(也称为睡眠等待)通过 time.sleep() 方法强制暂停脚本执行指定的秒数。
import time
driver.get("***")
time.sleep(5) # 等待5秒
# 继续脚本执行...
隐式等待设置了一个全局的等待时间,在这段时间内,Selenium会一直等待直到元素可被定位。
driver.implicitly_wait(10) # 设置隐式等待为10秒
# 定位元素,如果元素未立即出现,Selenium会等待最多10秒
element = driver.find_element(By.ID, 'elementid')
5.2.2 显式等待的高级用法
显式等待是一种更为灵活的等待方式,允许你在代码中设置条件,直到这些条件满足才继续执行脚本。显式等待通过 WebDriverWait 类结合 expected_conditions 模块来实现。
``` mon.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome() driver.get("***")
try: # 设置最长等待时间为20秒,直到id为'elementid'的元素可被点击 element = WebDriverWait(driver, 20).until( EC.element_to_be_clickable((By.ID, 'elementid')) ) element.click() # 点击元素 finally: driver.quit()
显式等待提供了对等待条件的细粒度控制,它既可以用于元素的可见性检查,也可以检查元素是否可被点击、是否存在于DOM中等多种条件。
## 5.3 模拟用户交互
模拟用户交互是自动化测试中非常重要的一个环节。这些交互可能包括拖放操作、键盘快捷键、文件上传下载等。
### 5.3.1 拖放操作与键盘快捷键
模拟拖放操作,通常使用`ActionChains`类。下面的代码展示了如何使用Selenium进行拖放操作。
```***
***mon.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("***")
# 使用ActionChains类模拟拖放操作
source = driver.find_element(By.ID, 'sourceid')
target = driver.find_element(By.ID, 'targetid')
action_chains = ActionChains(driver)
action_chains.click_and_hold(source).move_to_element(target).release(target).perform()
driver.quit()
模拟键盘快捷键操作则更直接,可以通过 send_keys() 方法发送键盘事件。
element = driver.find_element(By.ID, 'elementid')
element.send_keys(Keys.CONTROL, 'a') # 模拟Ctrl+A快捷键
5.3.2 文件上传与下载操作
文件上传通常涉及到定位到文件输入框,并发送文件路径给它。然而,Selenium没有提供直接的方法来模拟文件上传对话框,所以需要一些技巧来实现。
from selenium.webdriver.support.ui import Select
driver = webdriver.Chrome()
driver.get("***")
# 定位文件输入元素
file_input = driver.find_element(By.ID, 'fileinputid')
# 使用Select类选择文件路径
select = Select(file_input)
select.select_by_visible_text('C:\\path\\to\\your\\file.txt')
# 为了触发上传操作,可以模拟点击
upload_button = driver.find_element(By.ID, 'uploadbuttonid')
upload_button.click()
下载文件的自动化通常不建议使用Selenium直接进行,因为这会使自动化脚本与浏览器环境耦合过于紧密。更好的做法是使用后端服务或命令行工具进行文件下载操作。
在以上内容中,我们学习了网页交互操作和等待策略的核心知识,并通过代码块展示了如何在Selenium中实现这些操作。理解并熟练使用这些方法,能够有效地提高自动化测试和数据抓取的效率。
6. 异常处理技巧与数据抓取解决方案组合
在进行Selenium自动化测试或者数据抓取项目中,我们经常会遇到各种预料之外的异常情况。掌握有效的异常处理技巧,以及如何组合不同的技术解决方案,是提高项目健壮性和数据抓取成功率的关键。
6.1 异常处理机制
6.1.1 Selenium异常类型与捕获
Selenium框架在执行自动化脚本时,可能会遇到各种类型的异常,如元素找不到、超时、页面加载失败等。了解并识别这些异常类型是进行有效异常处理的前提。
``` mon.exceptions import NoSuchElementException, TimeoutException
try: element = driver.find_element_by_id("nonexistentelement") except NoSuchElementException: print("元素未找到异常") except TimeoutException: print("超时异常") except Exception as e: print(f"未知异常: {e}")
在上述代码中,通过try-except语句捕获了`NoSuchElementException`和`TimeoutException`两种常见的异常,并给出相应的提示信息。这有助于开发者快速定位问题所在。
### 6.1.2 日志记录与调试技巧
良好的日志记录习惯能够在遇到问题时提供关键信息,辅助我们快速地调试代码。Python的内置`logging`模块可以与Selenium结合使用,记录详细的执行过程。
```python
import logging
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
try:
# 你的Selenium代码
***("正在查找元素")
element = driver.find_element_by_id("element_id")
except Exception as e:
logger.error(f"发生错误: {e}")
日志记录模块不仅可以记录信息,还能记录错误和异常,为开发者提供调试时的宝贵线索。
6.2 数据抓取解决方案组合
6.2.1 Selenium与requests的结合
Selenium擅长处理动态网页和模拟用户行为,而requests库适合进行高效的静态网页数据抓取。将Selenium和requests结合使用,可以充分利用两者的优势,实现更全面的数据抓取。
import requests
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("***")
source_code = driver.page_source
driver.quit()
response = requests.get("***")
static_source_code = response.text
# 对比使用Selenium获取的动态页面源代码和requests获取的静态页面源代码差异
6.2.2 BeautifulSoup在数据解析中的应用
在获取网页源代码后,我们通常需要解析HTML文档以提取所需的数据。BeautifulSoup是一个强大的库,可以帮助我们快速解析HTML和XML文档。
from bs4 import BeautifulSoup
soup = BeautifulSoup(source_code, 'html.parser')
title = soup.find('title').get_text()
print(f"页面标题是: {title}")
通过上述示例,我们使用BeautifulSoup解析了网页源代码,并提取了页面标题。结合Selenium和requests,我们能够捕获页面在动态加载过程中的内容变化,并使用BeautifulSoup进行精细的数据提取。
6.3 实际应用案例分析
6.3.1 综合应用多种技术的数据抓取项目
在实际的数据抓取项目中,往往需要综合运用多种技术手段来达成目标。比如,我们可能需要先用Selenium获取动态加载的内容,然后用requests获取其他静态资源,最后用BeautifulSoup解析并提取数据。
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
# 使用Selenium模拟登录并获取动态内容
driver = webdriver.Chrome()
driver.get("***")
driver.find_element_by_id("username").send_keys("user")
driver.find_element_by_id("password").send_keys("pass")
driver.find_element_by_id("login_button").click()
driver.quit()
# 使用requests获取页面源代码
response = requests.get("***")
source_code = response.text
# 使用BeautifulSoup解析页面源代码并提取数据
soup = BeautifulSoup(source_code, 'html.parser')
data = soup.find_all('div', class_='data_class')
# 输出提取的数据
for item in data:
print(item.get_text())
6.3.2 处理动态内容与验证码的策略
针对包含动态内容和验证码的网页,我们可以使用Selenium来处理JavaScript渲染的内容,并采用验证码识别服务来绕过验证码。
``` mon.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome() driver.get("***")
等待验证码图片加载完成
captcha_img = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "captcha_image")) )
调用外部服务识别验证码
captcha_code = get_captcha_code_from_service(captcha_img)
输入识别的验证码
driver.find_element_by_id("captcha_input").send_keys(captcha_code) driver.quit()
def get_captcha_code_from_service(img_element): # 这里应该是调用外部服务API来获取验证码的值 return "1234" ```
在这个案例中,我们使用Selenium等待验证码图片加载并调用外部服务来识别验证码。验证码识别完成后,我们将识别的验证码输入到输入框中,并进行后续操作。这种方法要求我们拥有可靠的验证码识别服务,或者使用其他技术手段来绕过验证码。
通过结合使用Selenium、requests和BeautifulSoup,我们可以构建出健壮、高效的自动化数据抓取系统。在处理复杂的动态网页和验证码时,我们还需要借助其他技术或服务来提高自动化脚本的成功率和准确性。
简介:Selenium是一个强大的Web自动化测试工具,能够模拟用户行为进行网页交互。本项目“selenium_scraper”将展示如何利用Python的Selenium库进行网页数据抓取。项目包含源代码文件、配置文件、测试文件、依赖项、日志文件和数据存储等,涉及元素定位、交互操作、等待策略、JavaScript处理和异常处理等关键概念。开发者通过此项目可深入掌握复杂网页抓取技能,并结合requests和BeautifulSoup等库,打造高效灵活的数据抓取方案。
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)