
项目实训纪实(四)——DeepSeek+ollama+RAGFLow构建知识库
通过本次实践,我们成功实现了DeepSeek与RAGFlow的本地化融合部署,构建了一个具备语义检索能力的智能问答系统。该系统不仅能充分利用私有知识库提供精准、可追溯的回答,还具备良好的隐私保护与扩展性,为后续oj内应用大模型后端方法提供了支持。
这次任务的核心目标是结合DeepSeek和RAGFlow技术,实现本地化部署的模型知识库,提供个性化、隐私保护的智能问答服务。通过利用RAG技术(检索增强生成),我们可以结合外部算法博客,构建更加稳定的码风的代码。
一、RAG技术的介绍
RAG技术(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索与文本生成的技术,通过在生成回答前从外部知识库中检索相关信息,增强生成模型的上下文,从而提高生成内容的准确性和时效性。
与传统的生成模型不同,RAG技术不仅依赖于模型内部的知识,还能够实时访问外部的知识库,实时更新信息。这使得RAG特别适用于那些需要动态更新数据或信息量较少的领域,例如实时新闻、行业动态、客户支持等场景。
1.1 RAG技术的核心流程
RAG技术的核心流程可以分为以下三个步骤:
-
检索(Retrieval):当用户提出问题时,系统首先从外部的知识库中检索出与用户输入相关的文档片段。
-
增强(Augmentation):将检索到的信息与用户的输入结合,扩展模型的上下文。这一过程使得生成的答案更加精准,且能够包含更多外部知识。
-
生成(Generation):生成模型基于增强后的输入生成最终的回答。这个过程不仅依赖于模型的内部知识,还能够结合从外部知识库中检索到的信息,确保生成的内容更加准确且具有时效性。
1.2 RAG技术的应用场景
RAG技术能够广泛应用于以下几种场景:
| 应用场景 | 适用技术 | 描述 |
|---|---|---|
| 实时信息生成 | RAG | 适用于实时查询外部数据库、新闻、社交媒体等并生成答案,如天气预报、股市动态等。 |
| 企业知识库 | RAG | 企业可以构建自己的专有知识库,通过RAG技术实时查询企业的文档、规章制度等,以增强问答系统的准确性和时效性。 |
| 客户支持系统 | RAG | 客户问题常常涉及到实时的数据或文档,RAG技术可以快速检索并生成精准的解答,提升客服效率。 |
| 领域特定问答系统 | RAG | 适用于医学、法律、技术等特定领域,能够从专业文献中实时检索相关信息,为用户提供精准的解答。 |
二、使用ollama部署DeepSeek模型(详见博客二)
Ollama是一个用于本地运行和管理大语言模型(LLM)的工具。通过Ollama,我们能够在本地部署并运行DeepSeek等大模型,以便进行快速推理和微调。在本地部署Ollama时,涉及到一些关键的配置步骤,特别是环境变量的配置和端口放行,以确保虚拟机可以访问运行在本机上的Ollama模型。
1. 配置环境变量与端口访问
-
配置Ollama环境变量:默认情况下,Ollama模型只能允许本机访问(监听
localhost:11434)。为了让虚拟机能够访问本机上运行的Ollama模型,我们需要配置OLLAMA_HOST环境变量,使得虚拟机可以通过指定的IP地址访问Ollama。具体步骤如下:
-
打开终端,设置环境变量
OLLAMA_HOST为0.0.0.0:11434,这样可以让虚拟机和其他设备访问本机的Ollama模型:export OLLAMA_HOST=0.0.0.0:11434 -
配置完环境变量后,确认是否成功配置,可以通过运行
echo $OLLAMA_HOST来验证。
-
-
处理防火墙问题:如果虚拟机无法访问本机的Ollama模型,可能是由于本机防火墙阻止了端口
11434的访问。在这种情况下,需要放行该端口,允许外部设备通过该端口访问Ollama。-
在Windows中,可以通过控制面板访问防火墙设置,手动添加端口
11434的例外规则。 -
在Linux或Mac系统中,可以使用
ufw(Ubuntu)或iptables命令来开放端口:sudo ufw allow 11434
-
-
使用SSH端口转发:如果你希望只让虚拟机使用该端口,而不暴露给其他设备,你可以通过SSH端口转发来实现。SSH端口转发可以将本机的端口映射到虚拟机,使得虚拟机可以通过本地端口访问Ollama模型,而不会暴露给外部设备。
通过SSH端口转发的命令如下:
ssh -CNg -L 11434:127.0.0.1:11434 user@virtual_machine_ip该命令会将虚拟机上的
11434端口转发到本机的11434端口,从而使虚拟机能够通过本地地址访问Ollama。
2. 配置Ollama模型存储路径
默认情况下,Ollama会将模型下载到本机的C盘。如果你希望将模型下载到其他盘或自定义路径,可以在配置文件中进行设置。以下是配置存储路径的步骤:
-
打开Ollama的配置文件,找到
OLLAMA_MODELS设置项,并将其修改为你希望下载模型的路径。例如,将默认路径更改为D盘:export OLLAMA_MODELS=D:/OllamaModels -
保存配置文件,并重启Ollama服务。配置完后,所有模型将会下载到指定路径。
3. 下载并运行DeepSeek模型
-
下载DeepSeek模型:通过Ollama下载DeepSeek模型(如
deepseek-r1:32b)。执行以下命令来下载模型:ollama run deepseek-r1:32bOllama会自动从其模型库中下载并准备
deepseek-r1:32b模型,确保该过程在网络连接正常的情况下顺利进行。 -
验证模型运行:下载并加载模型后,可以通过Ollama提供的命令验证模型是否正确运行。通过执行以下命令来检查模型状态:
ollama status如果模型正确启动,你将看到模型的运行状态和资源占用情况。
三、下载RAGFLow源代码并完成配置
3.1 硬件要求
在正式开始部署前,请确保您的设备满足以下最低要求:
| 硬件/软件 | 要求 |
|---|---|
| 处理器(CPU) | 至少 4 核(x86 架构) |
| 内存(RAM) | 不低于 16 GB |
| 硬盘空间 | 至少预留 50 GB |
| Docker 版本 | ≥ 24.0.0 |
| Docker Compose | ≥ v2.26.1 |
| 操作系统 | 推荐使用 Linux(其他系统也可参考此流程) |
3.2 下载 RAGFlow 源码并切换版本
首先,克隆 RAGFlow 的 GitHub 仓库,并切换到稳定版本 v0.18.0:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/docker
git checkout -f v0.18.0
如需使用完整版 v0.18.0,请在 .env 文件中设置环境变量(默认版不带embedding模型):
RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0
3.3 启动 RAGFlow 服务
在 Docker 容器中运行 RAGFlow,可以选择使用 CPU 版或 GPU 加速版:
-
使用 CPU 启动:
docker compose -f docker-compose.yml up -d-
使用 GPU 启动(如有 NVIDIA 显卡):
docker compose -f docker-compose-gpu.yml up -d启动完成后,可通过以下命令查看服务日志并确认是否成功运行:
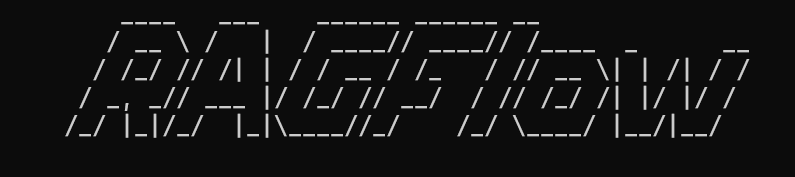
docker logs -f ragflow-server
成功,看到如下启动标识:
3.4配置RAGFLow模型
打开浏览器,在地址栏中输入:
http://你的服务器IP
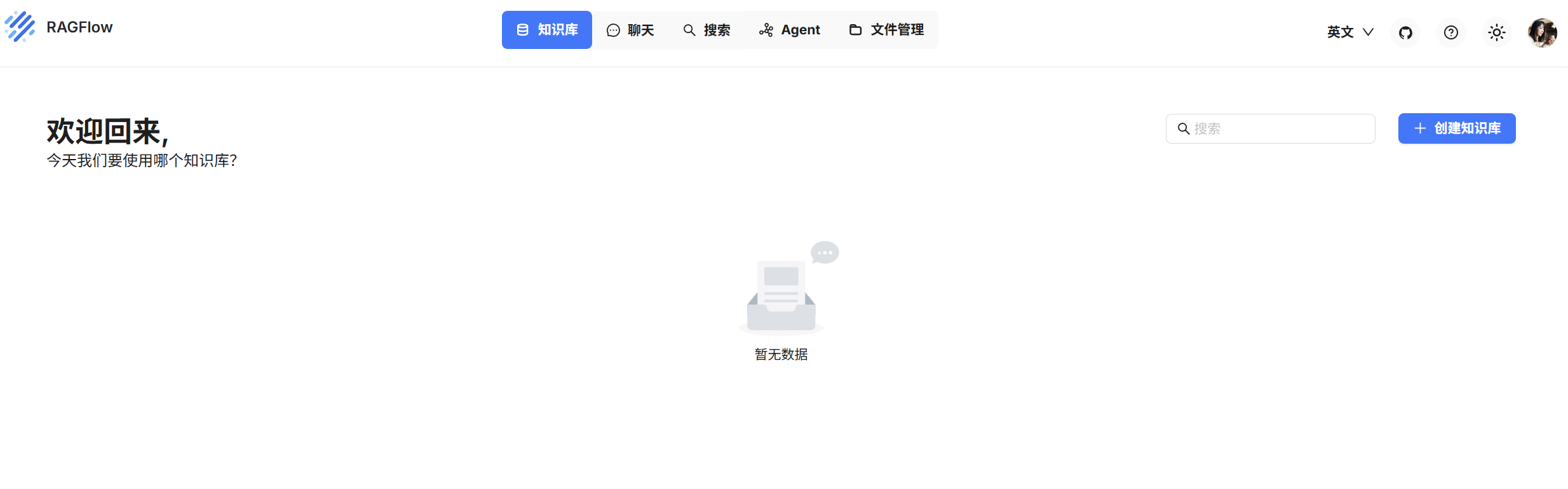
注册后可以看到上面的界面
四、配置 RAGFlow 并导入本地知识库
4.1 选择基础模型(使用 Ollama 提供的本地 LLM)
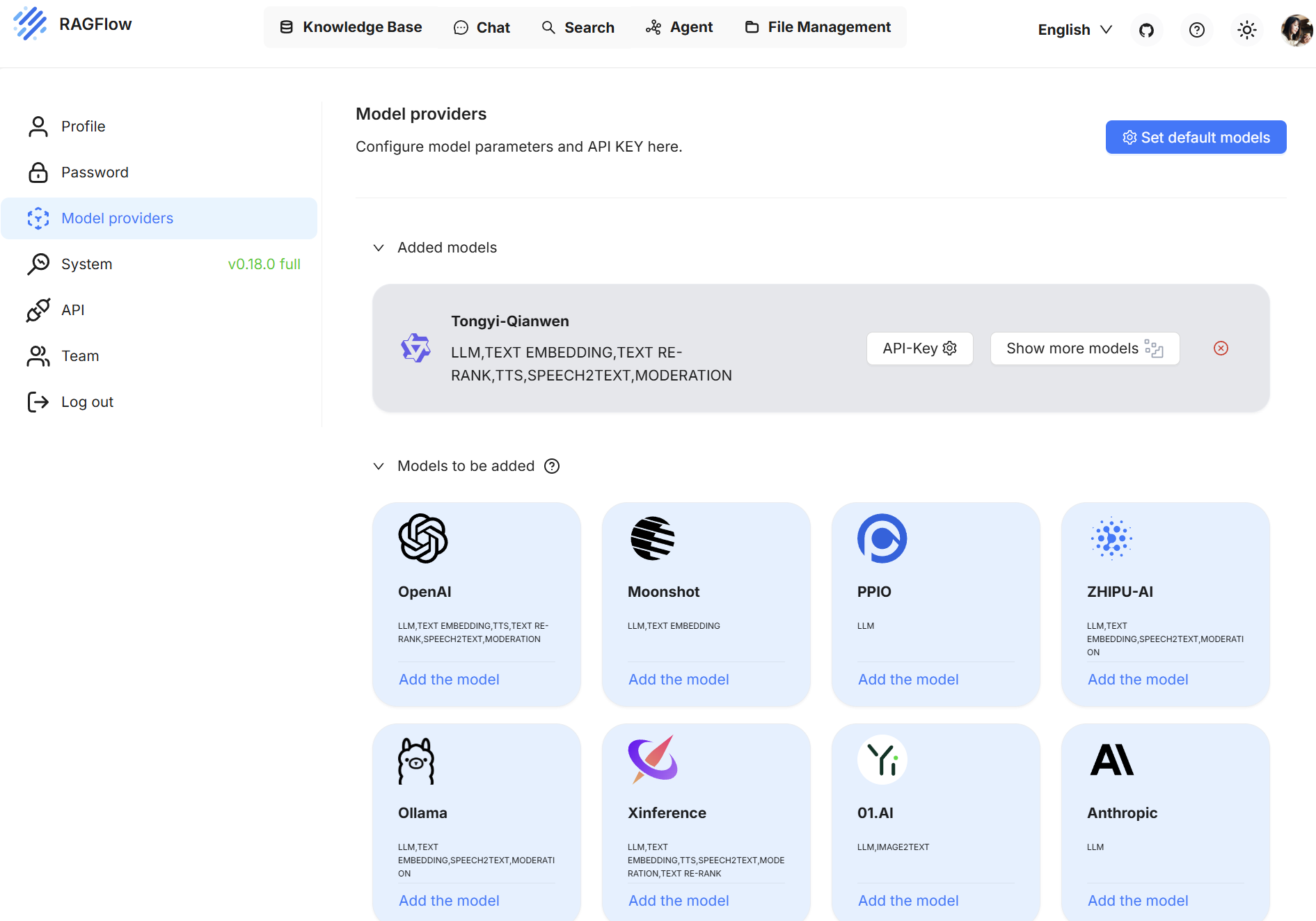
在进入 RAGFlow 页面后,点击右上角的用户头像,在下拉菜单中选择 Model Providers(模型提供者)。
-
点击 添加模型(Add Model)。
-
在弹出的界面中选择你希望接入的模型类型(此处选择 DeepSeek)。
-
填写必要的模型 API 地址(例如 Ollama 本地部署地址为:http://host.docker.internal:11434/v1/chat/completions)。
-
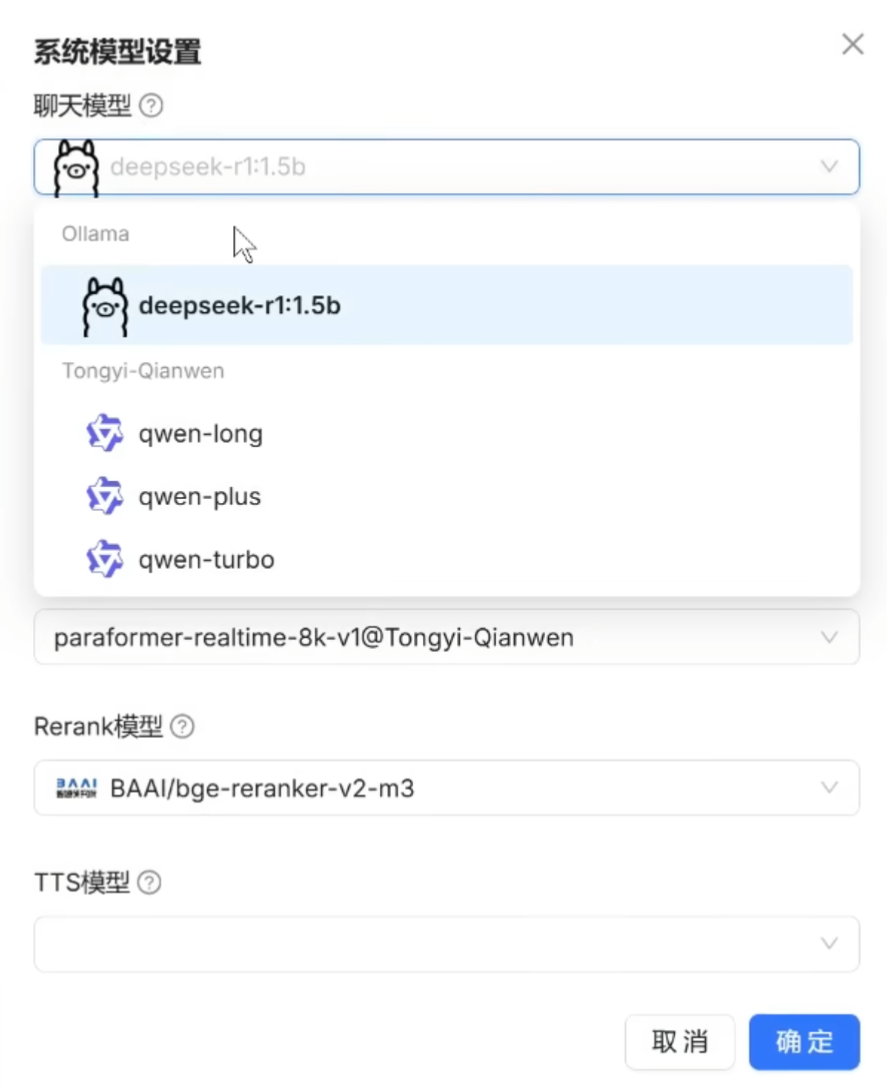
提交并保存后,点击“系统模型设置(System Model Settings)”,配置默认使用的:
-
Chat Model(对话模型);
-
Embedding Model(嵌入模型);
-
Image-to-Text Model(可选,非必须)
-
4.2 创建并配置知识库
-
在导航栏中点击 “Knowledge Base”(知识库)选项卡。
-
点击 “创建知识库(Create Knowledge Base)”,输入名称并确认。
-
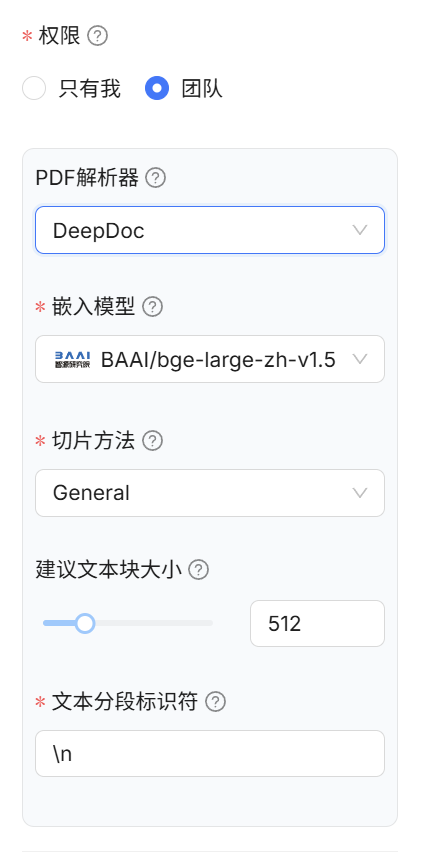
进入知识库后,点击“配置”按钮,进行如下设置:
-
选择所使用的嵌入模型(与上一步 Ollama 接入的 embedding 模型一致);
-
选择适配的“chunking 模板”,不同模板适合不同文档结构(推荐初学者使用
Auto模式); -
可以设置每个 chunk 的长度与重叠度,决定文本被切分为多大一段,适当调整可以提升检索效果。
-
4.3 导入文档并执行解析
知识库配置完成后,我们就可以将文档上传并转化为向量数据,实现语义检索。
-
点击知识库内的 “+ 添加文件” 按钮;
-
支持上传的格式包括:
-
文本类:PDF、DOC、DOCX、TXT、MD;
-
表格类:CSV、XLSX、XLS;
-
幻灯片类:PPT、PPTX;
-
图片类:JPG、PNG、GIF、TIF;
-
-
上传后点击文件右侧的 “播放按钮 ” 开始解析;
-
文件状态从 “Pending” 变为 “SUCCESS” 表示解析成功;
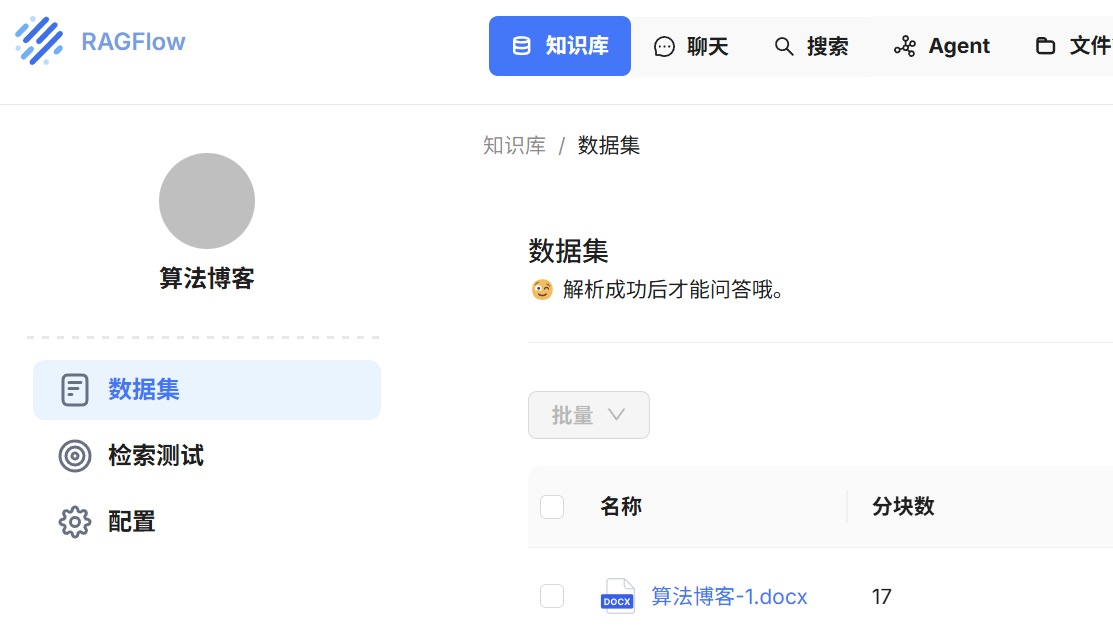
成功,本地知识库构建完毕
五、总结
通过本次实践,我们成功实现了DeepSeek与RAGFlow的本地化融合部署,构建了一个具备语义检索能力的智能问答系统。该系统不仅能充分利用私有知识库提供精准、可追溯的回答,还具备良好的隐私保护与扩展性,为后续oj内应用大模型后端方法提供了支持。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)