
[深度学习 - 发现有趣项目] 动漫图生成手绘草图 Anime2Sketch
我公司的科室开始在公众号上规划一些对外的技术文章了,包括实战项目、模型优化、端侧部署和一些深度学习任务基础知识,而我负责人体图象相关技术这一系列文章,偶尔也会出一些应用/代码解读等相关的文章。文章在同步发布至公众号和博客,顺带做一波宣传。有兴趣的还可以扫码加入我们的群。(文章有写的不好的地方请见谅,另外有啥错误的地方也请大家帮忙指出。)微信公众号:AI炼丹术技术交流群可以从公众号上获取,可以备注是
我公司的科室开始在公众号上规划一些对外的技术文章了,包括实战项目、模型优化、端侧部署和一些深度学习任务基础知识,而我负责人体图象相关技术这一系列文章,偶尔也会出一些应用/代码解读等相关的文章。
文章在同步发布至公众号和博客,顺带做一波宣传。有兴趣的还可以扫码加入我们的群。
(文章有写的不好的地方请见谅,另外有啥错误的地方也请大家帮忙指出。)微信公众号:AI炼丹术
【趣味AI项目】动漫图生成手绘草图 Anime2Sketch

技术简述
文章链接:https://arxiv.org/abs/2104.05703
代码链接:https://github.com/Mukosame/Anime2Sketch (基于上面文章实现的。)
(1)手绘草图生成
手绘草图生成的主要目的是从一张彩色实物图提取出它的素描勾线信息,类似于一个边缘轮廓检测的任务。实际上作者文章实现的是从草图到图像以及从图像到草图两个模块,也就是两个生成模型。
这里面主要存在的问题是缺少训练数据集,我们并不能找到一堆图像以及与之对应的草图。即使现在开源的一个草图数据集 SketchyCOCO 也没有完全一致的草图。(如下图,源自SketchyCOCO论文:https://arxiv.org/pdf/2003.02683.pdf)也就是一般解决训练集这个问题的做法是通过使用假草图来代替真实草图来训练。可以看出差距还是蛮大的,因此对模型的学习不太友好。
这里的论文(Adversarial Open Domain Adaption for Sketch-to-Photo Synthesis)的作者主要介绍一种开放域 open-domain的方式来混淆生成器,使生成器在真假学习之间有个模糊的界限,来解决上面所提到的问题。

(2)Anime2Sketch 效果展示
Anime2Sketch: A sketch extractor for illustration, anime art, manga
Anime2Sketch 源码实现的是从漫画到草图的生成,仓库代码开源于2021.4.8,但是只提供了测试代码以及预训练模型,并未开源训练代码及相关细节。而代码所使用的技术即论文(Adversarial Open Domain Adaption for Sketch-to-Photo Synthesis)。
测试了预训练效果,感觉还不错。可以通过模型,将自己在纸上手绘的图画转换成线稿图输入电脑进行上色。

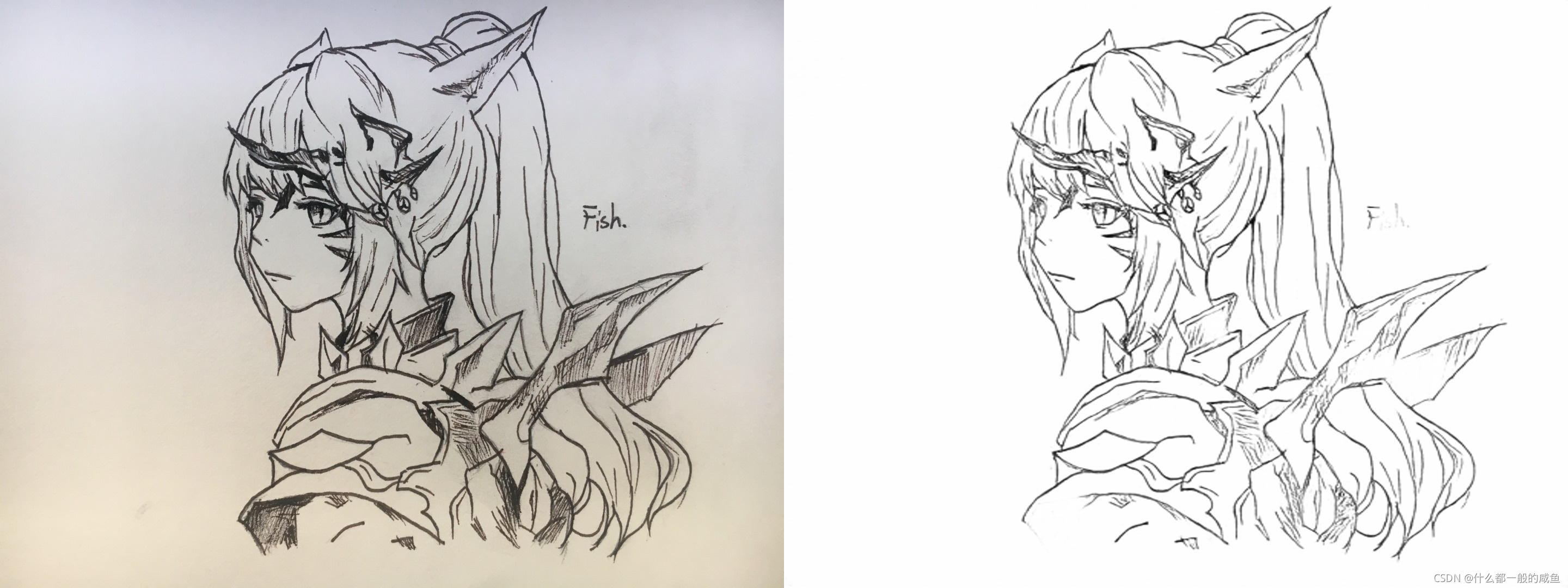
模型网络结构概述
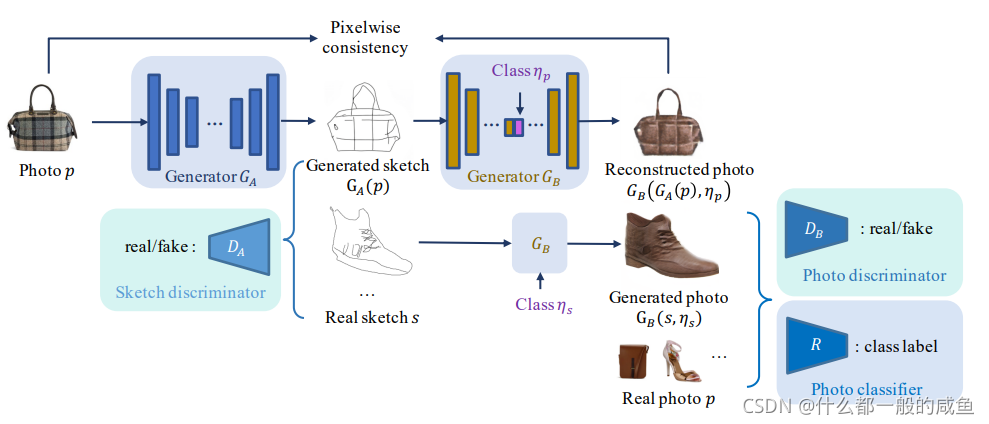
模型由两个生成模型、两个判别模型以及一个分类器组成。如上图所示,GA是一个真实图到草图的生成器、GB是一个草图到真实图的多类别生成器;DA、DB分别是草图判别器和真实图片判别器。除此之外还有一个分类器R。生成器的结构很简单,就是使用的Unet结构;判别器和分类器源码里面没有,论文里面也没提及具体结构。
模型这样做的特点是可以使用不成对的草图和真实图像数据进行训练。理由如上面说的,数据集方面我们很难去收集到成对的真实图片及其草图。因此模型不要求你每个图片都有唯一一个标签,但是需要图片有其相应类别。
主要通过优化训练策略,是模型学习到图片到草图和草图到图片的联合转化,减小合成草图和真实草图的domain gap。
代码实战
(1)运行环境
环境很简单,而且不一定需要gpu,模型在cpu下也能运行。
Python:3.7
torch
torchvision
Pillow
gradio
torchtext
(2)运行步骤
① 从github 上将代码clone下来;
git clone https://github.com/Mukosame/Anime2Sketch.git
cd Anime2Sketch
② 安装python依赖包;
pip install -r requirements.txt
③ 下载预训练模型;
-
从这个链接下载预训练模型 netG.pth :https://drive.google.com/drive/folders/1Srf-WYUixK0wiUddc9y3pNKHHno5PN6R?usp=sharing ;
-
并放入目录下weights文件夹:./Anime2Sketch/weights。
④ 测试图片(模型推理);
- 将需要测试的图片放入默认文件夹:test_samples;
python test.py --dataroot test_samples --load_size 512 --output_dir results
- 运行完毕会在同个目录下生成文件夹:results,存放草图提取后的图像。
代码分析
(1)参数设置
‘dataroot’: 指需要运行的图片目录,会将目录下所有图片都进行前向推理;
‘load_size’: 模型输入的大小;(不需要改);
‘output_dir’: 前向推理完生成的图片保存的文件夹;
‘gpu_ids’: 指定所使用的GPU,如果使用cpu则 default=[] 即可;
parser = argparse.ArgumentParser(description='Anime-to-sketch test options.')
parser.add_argument('--dataroot','-i', default='test_samples/', type=str)
parser.add_argument('--load_size','-s', default=512, type=int)
parser.add_argument('--output_dir','-o', default='results/', type=str)
parser.add_argument('--gpu_ids', '-g', default=[0], help="gpu ids: e.g. 0 0,1,2 0,2.")
(2)前向推理
-
创建模型;
由于作者并未提供训练的代码,而测试(前向推理)的时候只需要生成模型即可,因此创建模型的时候只创建了动漫到草图的生成模型。
def create_model():
"""Create a model for anime2sketch
hardcoding the options for simplicity
"""
norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
net = UnetGenerator(3, 1, 8, 64, norm_layer=norm_layer, use_dropout=False)
ckpt = torch.load('weights/netG.pth')
for key in list(ckpt.keys()):
if 'module.' in key:
ckpt[key.replace('module.', '')] = ckpt[key]
del ckpt[key]
net.load_state_dict(ckpt)
return net
model = create_model().to(device) # create a model given opt.model and other options
model.eval()
-
模型推理
遍历测试文件夹,并将每张图片输入模型生成草图,最终保存到输出文件夹。
for test_path in test_list:
basename = os.path.basename(test_path)
aus_path = os.path.join(save_dir, basename)
img, aus_resize = read_img_path(test_path, opt.load_size)
aus_tensor = model(img.to(device))
aus_img = tensor_to_img(aus_tensor)
save_image(aus_img, aus_path, aus_resize)
拓展
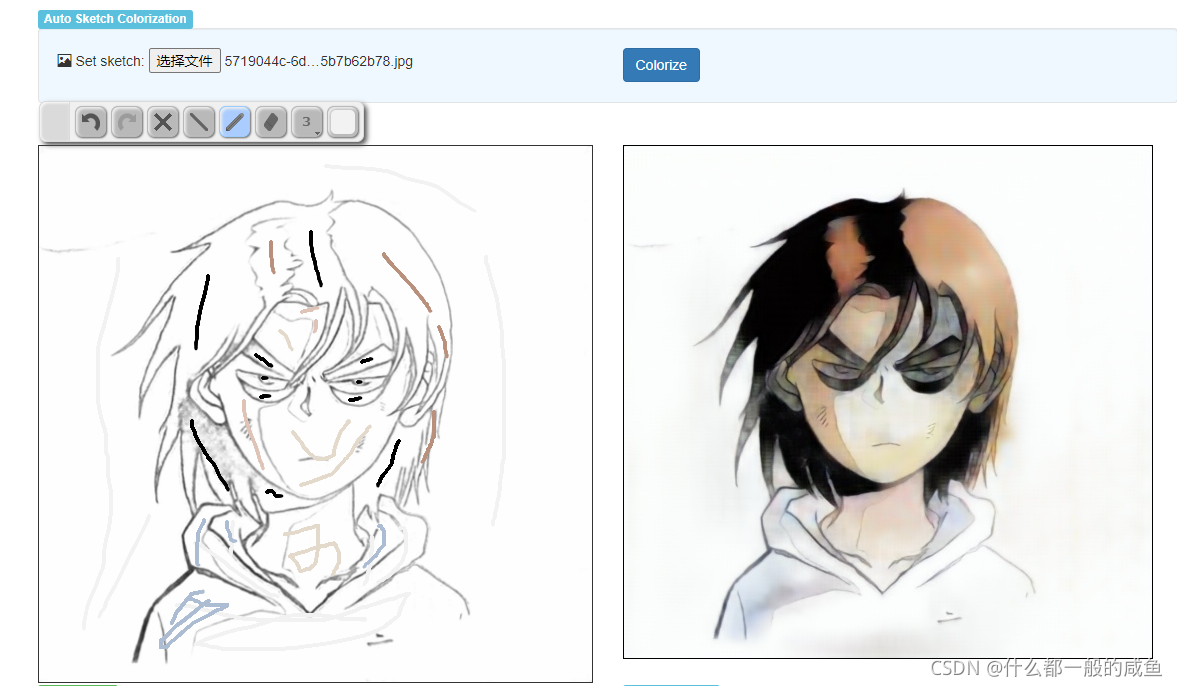
虽然没有提供动漫线稿还原成彩色原图的代码,但小编在这里找到了一个自动上色的项目。
代码:https://github.com/pfnet/PaintsChainer;(可以通过代码在本地启一个上色服务。)
也可以直接通过官方demo网站:http://paintschainer.preferred.tech/
-
可以自动上色。(好像官方demo的版本效果会比他们提供的预训练模型好)
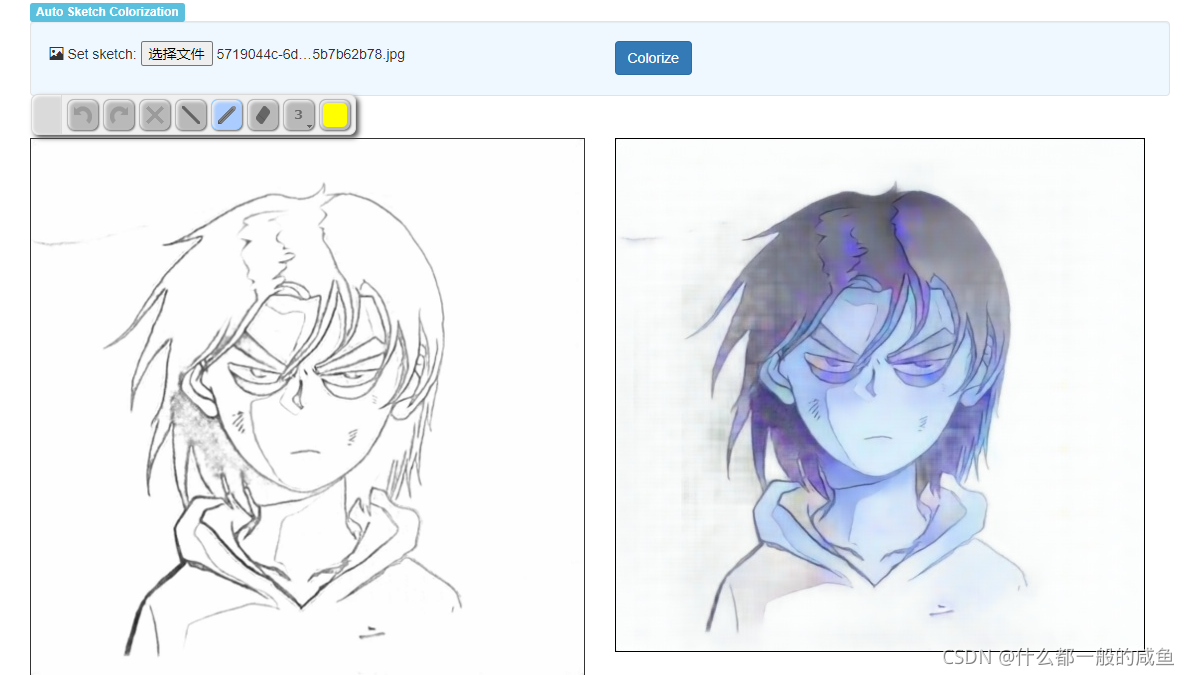
-
也可以提前勾画部分区域的颜色,再自动上色,这样会更加自然。具体大家可以自行下载下来玩。
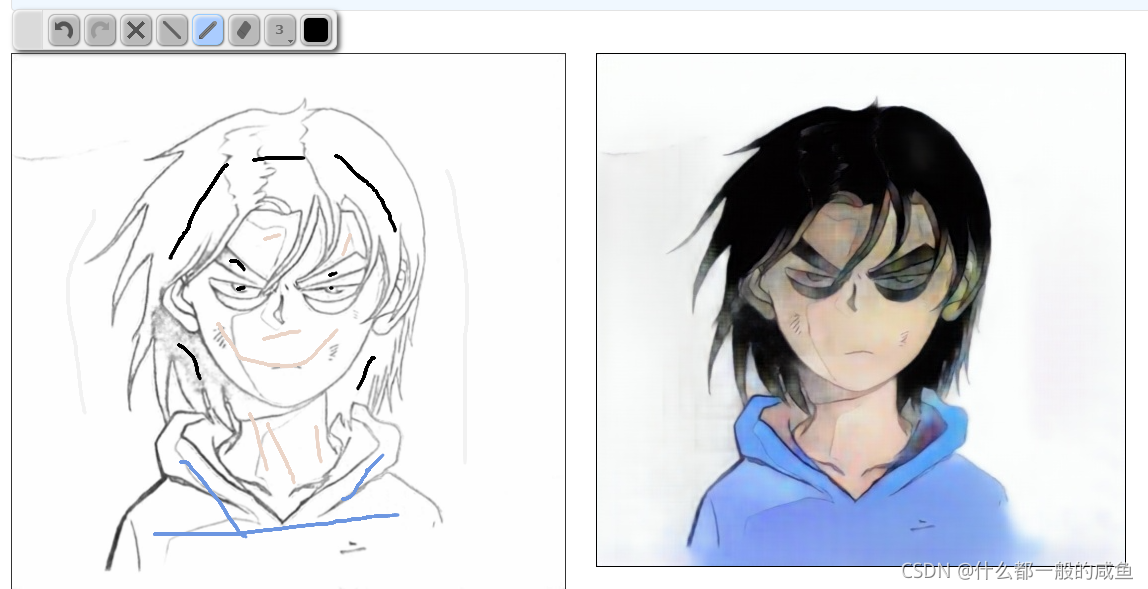
参考文献
(1)论文笔记“Adversarial Open Domain Adaption for Sketch-to-Photo Synthesis:https://zhuanlan.zhihu.com/p/395055283.
(2)Adversarial Open Domain Adaption for Sketch-to-Photo Synthesis Supplementary Material:https://arxiv.org/pdf/2104.05703.pdf
(3)The Sketchy Database: Learning to Retrieve Badly Drawn Bunnies:http://sketchy.eye.gatech.edu/paper.pdf
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)