
Halcon 深度学习--手写数字分类(亲测)
Halcon 版的深度学习,操作简单。
·
环境配置
halcon开发版本 :MVTec HALCON HDevelop 21.05
系统版本:Windows10 64位
话不多说,直接开搞。第一张是原图,第二张是检测出来的图。

* Preprocess_Image and make DLDataset
* 导入需要训练的模型,这里是分类模型,halcon安装目录里就有,在安装目录的‘dl’文件夹中
* 需要修改读入模型的路径
read_dl_model('pretrained_dl_classifier_alexnet', DLClassifierHandle)
* 导入需要训练的数据集(保存Mnist手写数据集,加入其他需要训练的图片)
* 数据集没有区分train/test, 只有标签0,1,2,3……,每个子文件夹有5000~7000左右不等的图片
* 数据集中的图片都是28*28*3尺寸和维度的,黑底白字
* 原图(需要作成数据集的图片集合)存放位置,读者可自行修改,
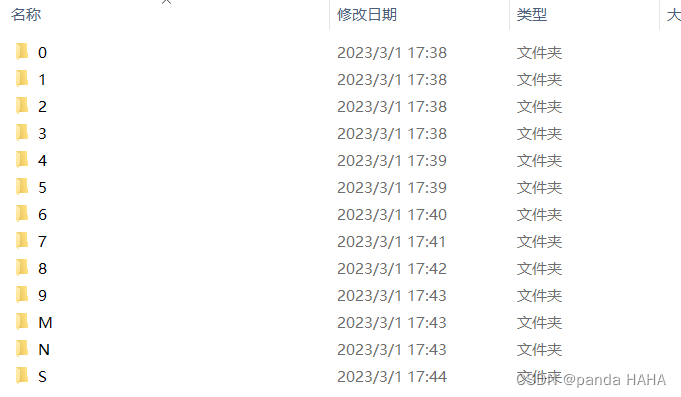
* 我这里是包含0~9个数字子文件夹,以及字母M,N,S子文件夹
Image_dir := 'mnist_all'
* 找到子目录
list_files (Image_dir, 'directories', ImageFiles)
* 将子目录,作为DLdataset数据集的分类标准(标签)
read_dl_dataset_classification (ImageFiles, 'last_folder', DLDataset)
* 训练集,验证集,测试集的分割比例
TrainingPercent := 70
ValidationPercent:= 15
* 按照比例进行分割数据
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, [])
*获取作成DLdataset的class_names作为标签(子目录)
*Class_names:=['0','1','2','3','4','5','6','7','8','9','M','N','S']
get_dict_tuple(DLDataset, 'class_names', Class_names)
*获取DLDataset的samples作为新的Samples,每张图片都是一个sample
get_dict_tuple (DLDataset, 'samples', Samples)
*获取Samples的每一个的图片的名字(子目录 + xx.jpg)赋值给ImageFileName
get_dict_tuple (Samples[0], 'image_file_name', ImageFileName)
*从模型中获取预处理的参数
create_dict (GenParam)
set_dict_tuple (GenParam, 'overwrite_files', true)
* DLPreprocessParam 为前处理的所有参数集合,便于用于infer时对图片进行预处理
create_dl_preprocess_param_from_model (DLClassifierHandle, 'none', 'full_domain', [], [], [], DLPreprocessParam)
* 按照前处理的这些参数的设置值,对数据集的图片进行前处理,创建在data_num_character文件夹中,
preprocess_dl_dataset (DLDataset, 'data_num_character', DLPreprocessParam, GenParam, DLDatasetFileName)mnist_all文件夹,左侧是所有子目录(分类的名字),右侧是0 这个文件夹里面的内容。所有的文件夹中的图片为85341张图。
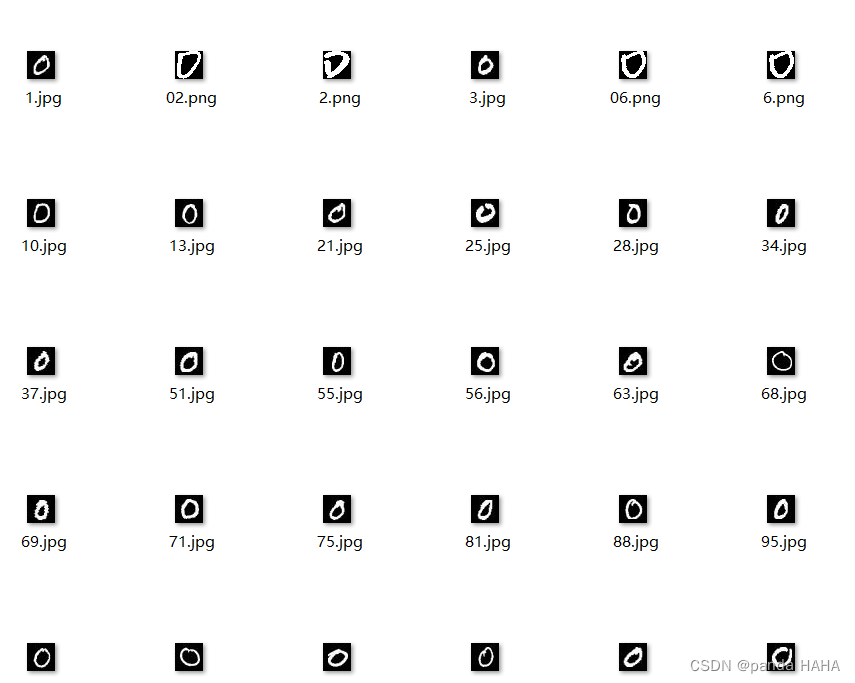
以下即为作成的DLdataset ,也就是文件夹data_num_character中,samples中就是所有的图片处理, dl_dataset.hdict就是最终需要输入进模型的数据集。
接下来就可以开始设置训练模型的参数,然后开始训练。
* train
* 设置训练模型为CPU
set_dl_model_param (DLClassifierHandle, 'runtime', 'cpu')
* 设置模型分类的类别
set_dl_model_param(DLClassifierHandle, 'class_names', Class_names)
*设置迭代数epoch
NumEpochs := 10
* 设置每次输入的图片批次数batch_size,也就是一下子输入batch_size张图片
* batch/batch_size/Epoch 的关系:
* batch = 总图片数/batch_size
* epoch=1 就要有batch次训练,等到所有的batch训练完,才会进入epoch=2的训练
set_dl_model_param (DLClassifierHandle, 'batch_size', 28)
* 设置学习率,python 中对应的就是lr
set_dl_model_param (DLClassifierHandle, 'learning_rate', 0.001)
*绘制出每隔n个历时的训练和验证误差
PlotEveryNthEpoch := 0.5
*定期降低学习率以理想地微调你的分类器。
LearningRateStepEveryNthEpoch := 6
LearningRateStepRatio := 0.1
*创建模型训练的参数
create_dl_train_param (DLClassifierHandle, NumEpochs, 1, 'true', 42, [], [], TrainParam)
* 进行模型训练
train_dl_model (DLDataset, DLClassifierHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos)模型训练的界面就如下图所示:
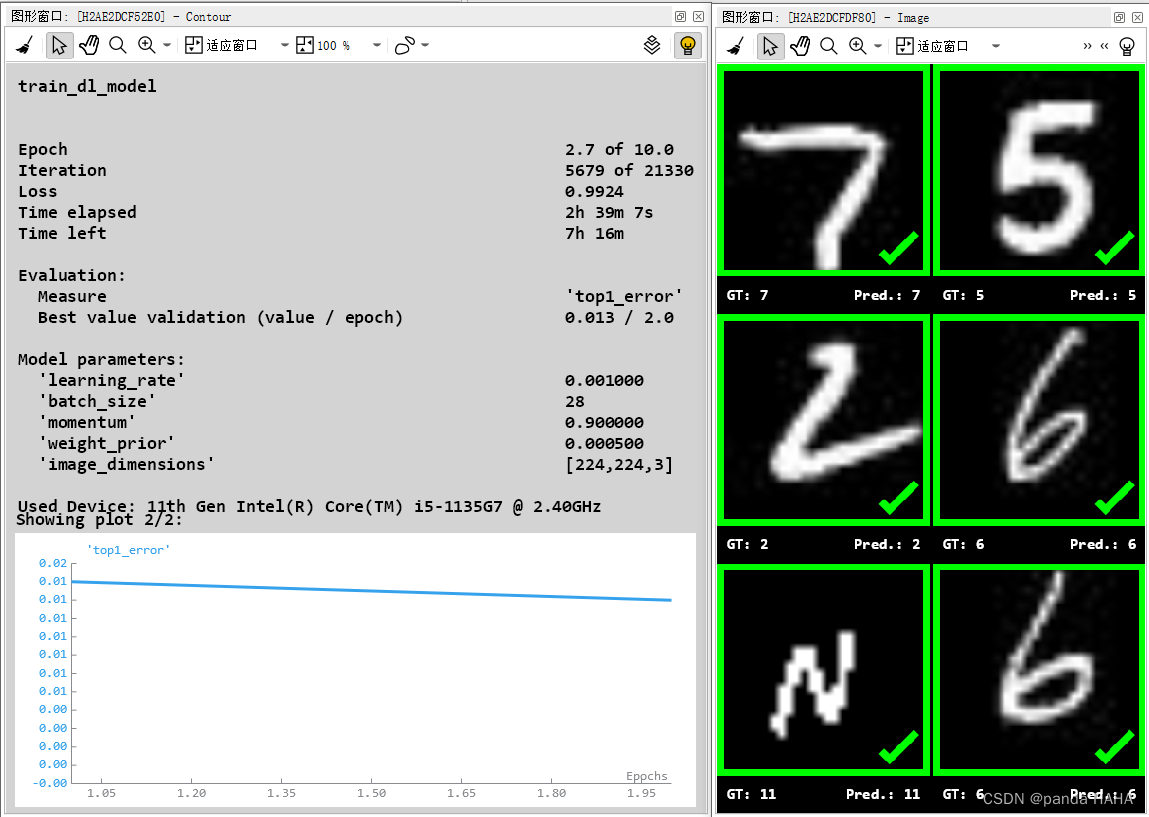
模型训练过后,需要对保存下来的模型进行模型验证,去查验训练好的模型的准确率情况,具体的指标为图像分类的指标:
top1_error /precision/ recall / f-score / confusion_matrix
* Validation
* 设置验证过程的参数
create_dict (GenParamEval)
set_dict_tuple (GenParamEval, 'class_names_to_evaluate', 'global')
* 图像分类的指标,top1_error/precision/recall/f-score/confusion_matrix
set_dict_tuple (GenParamEval, 'measures', ['top1_error','precision','recall','f_score','absolute_confusion_matrix'])
* 模型验证
evaluate_dl_model (DLDataset, DLClassifierHandle, 'split', ['validation','test'], GenParamEval, EvaluationResult, EvalParams)
*模型验证的可视化过程
create_dict (EvalDisplayMode)
* 可视化过程以饼图显示
set_dict_tuple (EvalDisplayMode, 'display_mode', ['measures','pie_charts_precision','pie_charts_recall','absolute_confusion_matrix'])
create_dict (WindowDict)
* 窗口显示模型验证的结果
dev_display_classification_evaluation (EvaluationResult, EvalParams, EvalDisplayMode, WindowDict)
* 销毁所有的验证可视化的窗口
*dev_display_dl_data_close_windows (WindowDict)接下来,就是模型训练完成了,可以用新模型来进行预测新的图片了。
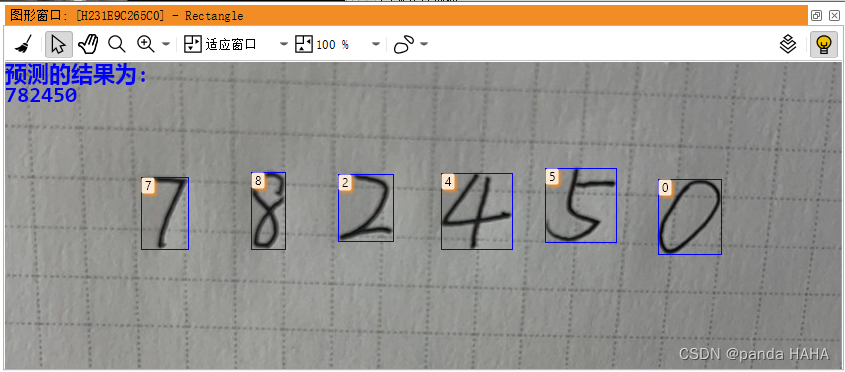
自己手写了一个比较规范的数字,进行识别。需要将一张图片进行一个一个数字切割,然后去应用模型进行识别。
推论:需要识别数字,找到数字的轮廓,画出最小矩形,然后保存到文件夹中。不需要保存到文件中,直接进行检测。原因是如果需要检测的字符多了,可能就会存在文件读取图像数据的路径顺序和原本字符数据会出现对应不上的问题。
**可供参考 infer
read_image (Image, '88.jpg')
threshold (Image, Region, 0, 128)
connection (Region, ConnectedRegions)
* 把图片中的横线竖直线去掉
erosion_rectangle1 (ConnectedRegions, RegionErosion, 5, 5)
gen_contour_region_xld (RegionErosion, Contours, 'border')
dilation_rectangle1 (RegionErosion, RegionDilation, 5, 5)
union1 (RegionDilation, RegionUnion)
* 找出轮廓
gen_contour_region_xld (RegionUnion, Contours, 'border')
* 对轮廓填充
gen_region_contour_xld(Contours, Region1, 'filled')
* 根据面积选择
select_shape (Region1, SelectedRegions, 'area', 'and', 100, 99999)
* 对数字进行排序,从左到右的顺序
sort_region (SelectedRegions, SortedRegions, 'character', 'true', 'row')
*画出最小外接矩形
smallest_rectangle1(SortedRegions, Row1, Column1, Row2, Column2)
count_obj(SortedRegions, Number)
tuple_gen_const (Number, 0, Newtuple)
for Index := 0 to Number-1 by 1
* 根据坐标画出矩形,可以适当缩放一下,识别会更加准确
gen_rectangle1 (Rectangle, Row1[Index]-10, Column1[Index]-10, Row2[Index]+10, Column2[Index]+10)
* 根据画出的矩形获取原图想要的矩形
reduce_domain (Image, Rectangle, ImageReduced1)
* 只裁剪出原图中矩形的图片
crop_domain (ImageReduced1, ImagePart)
* 转为黑白图
rgb1_to_gray (ImagePart, GrayImage)
* 对黑白图片进行翻转,变成黑底白字
invert_image (GrayImage, ImageInvert)
rgb1_to_gray (ImageInvert, GrayImage2)
* 加强图片
emphasize (GrayImage2, ImageEmphasize, 11, 11, 1)
*对图片进行统一的前处理
gen_dl_samples_from_images (ImageEmphasize, DLSampleBatch)
preprocess_dl_samples(DLSampleBatch, DLPreprocessParam)
*加载并且使用训练好的模型进行识别
apply_dl_model(DLModelHandle, DLSampleBatch, [], DLResultBatch)
* 获取预测的所有类(降序排列)
get_dict_tuple (DLResultBatch, 'classification_class_names', Classesname)
* 获取所有类的概率列表
*get_dict_tuple (DLResultBatch, 'classification_confidences', Confidences)
* 获取置信度/概率最大的预测类的名称
Text := Classesname[0]
Newtuple[Index] := Text
endfor 最后将预测结果显示在窗体上。
*画出矩形图
gen_rectangle1 (Rectangle, Row1, Column1, Row2, Column2)
dev_display (Image)
* 显示为边框
dev_set_draw ('margin')
* 展示图片,矩形框,以及预测的值,在图片的左上角
dev_display (Rectangle)
dev_disp_text (Newtuple, 'image', Row1, Column1, 'black', [], [])
set_display_font (WindowHandle, 20, 'mono', 'true', 'false')
dev_set_color ('blue')
set_tposition (WindowHandle, 0, 0)
write_string (WindowHandle, '预测的结果为:')
set_tposition (WindowHandle, 20, 0)
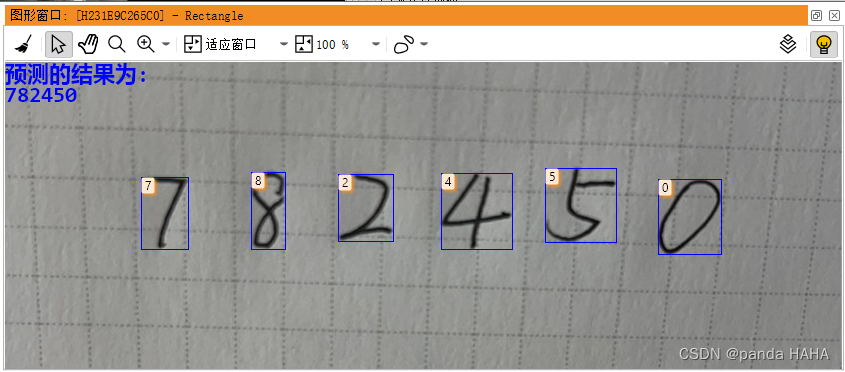
write_string (WindowHandle, Newtuple)最后放张展示图片,最后推论的结果图
基本上就是这么个流程。
感谢!
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)