
CV面试题目总结(一)- 深度学习算法
注:由于面试官面试的针对人脸识别项目,所以问的人脸识别相关题目比较多。目录1.介绍一下人脸识别项目。2.PCA是什么?3.常用聚类算法有哪些?4.解释一下KNN、K-means。5.有哪些数据增强算法?为什么要进行数据增强?6.什么是二阶段网络?7.直方图是什么?它的作用?8.介绍一下YOLOV3,说明一下优缺点。9.什么是margin?10.介绍一下MTCNN网络,什么是P-Net、R-Net、
注:由于面试官面试的针对人脸识别项目,所以问的人脸识别相关题目比较多。
目录
10.介绍一下MTCNN网络,什么是P-Net、R-Net、O-Net?
16.人脸识别是侧脸的时候怎么检测?是否考虑过由距离确定人脸?
18.怎么改进FaceNet网络?或者用哪些更好的网络进行替换?
1.介绍一下人脸识别项目。

(1)首先利用dlib进行人脸的数据集采集和建立
1)通过摄像头采集人脸图像。
2)建立人脸图像的label信息。
3)建立个人人脸数据库。
(2)数据库初始化
1)遍历数据库中所有的图片。
2)检测每个图片中的人脸位置。
3)利用MTCNN将人脸截取下载。
4)将获取到的人脸进行对齐。
5)利用FaceNet将人脸进行编码。
6)将所有人脸编码的结果放在一个列表中,同时也会将它们的名字放入列表中,这两个列表中的相同位置的元素都是对应的,方便后面根据对应的编码的索引找到名字,然后实时显示在检测结果中。
第6步得到的列表就是【已知的所有人脸】的特征列表,在之后获得的实时图片中的人脸都需要与已知人脸进行比对,这样我们才能知道谁是谁。
(3)实时图片的处理
1)人脸的截取与对其。
2)利用FaceNet对矫正后的人脸进行编码。
3)将实时图片中的人脸特征与数据库中的进行对比。
(4)对比过程
1)获取实时图片中的每一张人脸特征。
2)将每一张人脸特征和数据库中所有的人脸进行比较,计算距离。如果距离小于阈值,则认为其具有一定的相似度。
3)获得每一张人脸在数据库中最相似的人脸的序号。
4)判断这个序号对应的人脸距离是否小于阈值,是则认为人脸识别成功,她就是这个人。
2.PCA是什么?
PCA(Principal Component Analysis) 是一种常见的数据分析方式,常用于高维数据的降维,可用于提取数据的主要特征分量。
3.常用聚类算法有哪些?
K-means(k均值)、GMM(高斯混合模型)、Mean-Shift(均值漂移)等
4.解释一下KNN、K-means。
(1)KNN
KNN也叫K近邻算法,简而言之,可以认为是K个最近的邻居,当K等于1的时候,就是寻找那一个离他最近的邻居。用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
KNN中的核心思想就是当我们无法判定当前待分类的点是属于已知类别中的哪一类时,我们可以根据统计学的理论来看看它所在位置的特征,衡量它周围邻居的权重,最终将它归为权重最大的那一类。
(2)K-means
首先我们需要选择K个类中心点,这些点一般是从数据集中随机抽取出来的;
然后将每一个样本都分配到离它最近的类中心点,这么就形成了K个类,然后重新再计算每个类的中心点;
一直重复上一步,直到类不发生变化,或者你也可以设置最大迭代次数,当达到这个迭代次数的时候,就会结束运行。
(3)两者的区别与联系
1)它们都是用于解决数据挖掘的算法。K-Means是聚类算法,KNN是分类算法。
2)K-Means是非监督学习,KNN是有监督学习。是否为监督学习在于看是否需要我们给出训练数据的分类标识。
3)K-Means中的K代表K类,而KNN中的K代表K个最近的邻居。
5.有哪些数据增强算法?为什么要进行数据增强?
(1)数据增强的方法
1,数据翻转:数据翻转是一种常用的数据增强方法,这种方法不同于旋转 180 °。这种方法是做一种类似于镜面的翻折。
2,数据旋转:旋转就是顺时针或者逆时针的旋转,注意在旋转的时候, 最好旋转 90 - 180 度否则会出现尺度的问题
3,图像缩放:图像可以被放大或缩小。放大时,放大后的图像尺寸会大于原始尺寸。大多数图像处理架构会按照原始尺寸对放大后的图像进行裁切而图像缩小会减小图像尺寸,这使我们不得不对图像边界之外的东西做出假设。
4,图像剪裁:这种方法更流行的叫法是随机裁剪,我们随机从图像中选择一部分,然后降这部分图像裁剪出来,然后调整为原图像的大小
5,图像平移:平移是将图像沿着 x 或者 y 方向 (或者两个方向) 移动。我们在平移的时候需对背景进行假设,比如说假设为黑色等等,因为平移的时候有一部分图像是空的,由于图片中的物体可能出现在任意的位置,所以说平移增强方法十分有用。
6,添加噪声:过拟合通常发生在神经网络学习高频特征的时候 (因为低频特征神经网络很容易就可以学到,而高频特征只有在最后的时候才可以学到) 而这些特征对于神经网络所做的任务可能没有帮助,而且会对低频特征产生影响,为了消除高频特征我们随机加入噪声数据来消除这些特征。
(2)为何要进行数据增强呢?
在深度学习中,一般要求样本的数量要充足,样本数量越多,训练出来的模型效果越好,模型的泛化能力越强。但是实际中,样本数量不足或者样本质量不够好,这就要对样本做数据增强,来提高样本质量。
关于数据增强的作用总结如下:
1,增加训练的数据量,提高模型的泛化能力
2,增加噪声数据,提升模型的鲁棒性
6.什么是二阶段网络?
目标检测算法分为单阶段和双阶段两大类。单阶段目标验测算法(one-stage),代表算法有 yolo 系列,SSD 系列;直接对图像进行计算生成检测结果,检测速度快,但检测精度低。双阶段目标验测算法(two-stage),代表算法 RCNN 系列;先对图像提取候选框,然后基于候选区域做二次修正得到检测点结果,检测精度较高,但检测速度较慢。(单阶段偏应用,因为在精度没有差很多的情况下,速度很快,就会选择单阶段目标检测算法;双阶段偏比赛,只注重精度高低,速度不考虑)
7.直方图是什么?它的作用?
(1)什么是直方图
直方图显示图像数据时会以左暗右亮的分布曲线形式呈现出来,而不是显示原图像数据,并且可以通过算法来对图像进行按比例缩小,且具有图像平移、旋转、缩放不变性等众多优点。直方图在进行图像计算处理时代价较小,所以经常用于图像处理!
(2)直方图的常见作用有以下三点
1、显示质量波动的状态;
2、较直观地传递有关过程质量状况的信息;
3、通过研究质量波动状况之后,就能掌握过程的状况,从而确定在什么地方集中力量进行质量改进工作。
8.介绍一下YOLOV3,说明一下优缺点。
(1)YOLOV3

YOLOV3网络主要由以下几个部分组成:
- 输入
- 基础网络:基础网络可以根据具体需求选择,原论文中作者使用的是DarkNet-53
- YOLOv3
网络部件介绍:
1)DBL:也就是代码中的Darknetconv2D_BN_Leaky,是YOLOv3的基本组件。就是卷积+BN+Leaky relu。BN和Leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
2)resn:n代表数字,有res1,res2,……,res8等等,表示Res_block里面含有多个Res_unit。这是YOLOv3的大组件,YOLOv3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从YOLOv2的DarkNet-19上升到YOLOv3的DarkNet-53,前者没有残差结构)。
3)concat:张量拼接。将DarkNet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作时不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
YOLOv3网络的三个分支:
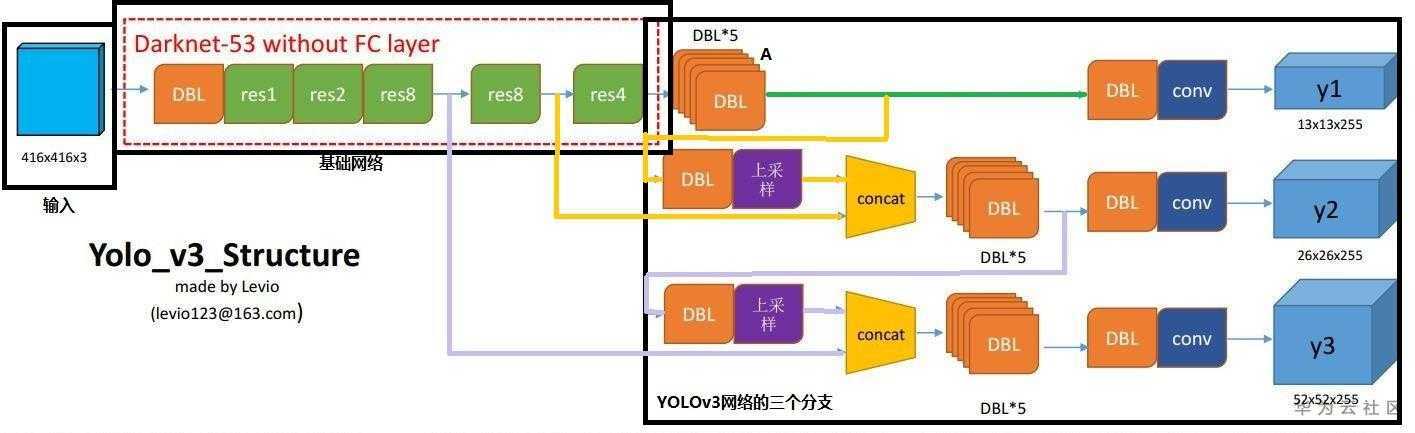
①多尺度检测-y1(13x13x255)
使用目标:大目标
路径:绿色线标注
输出维度:13x13x255
输出维度具体解释:13x13:图片大小;255=(80+5)x3;80:识别物体种类数;5=x,y,w,h和c(置信度);3:每个点预测3个bounding box。
②尺度检测-y2(26x26x255)
适用目标:中目标
路径:黄色线标注
输出维度:26×26×255
输出维度具体解释:26×26:图片大小;255=(80+5)×3;80:识别物体种类数;5=x,y,w,h和c(置信度);3:每个点预测3个bounding box。
③尺度检测-y3(52x52x255)
适用目标:小目标
路径:紫色线标注
输出维度:52×52×255
输出维度具体解释:52×52:图片大小;255=(80+5)×3;80:识别物体种类数;5=x,y,w,h和c(置信度);3:每个点预测3个bounding box。
(2)优点
- 快速,pipline简单
- 背景误检率低
- 通用性强
(3)缺点(相比RCNN系列物体检测方法,YOLO具有以下缺点:)
- 识别物体位置精准性差
- 召回率低
9.什么是margin?
二分类问题中的分类规则,或者说决策函数通常为:

(其它很多说法,这里的判定是 f(x) 而不是 yf(x) )
可以看到:
如果 𝑦𝑓(𝑥)>0,即𝑦与𝑓(𝑥)同号,则判定样本分类正确
如果 𝑦𝑓(𝑥)<0,即𝑦与𝑓(𝑥)异号,则判定分类错误
相应的决策边界都为 𝑓(𝑥)=0
𝑦𝑓(𝑥) 被称为margin(函数间隔),其作用类似于回归问题中的残差 𝑦−𝑓(𝑥)。
这里还要提一下,函数间隔𝑦𝑓(𝑥) 的值如果越大(或者越小) 说明样本离分类平面越远,分类确信度越高。(配合下图理解)

所以最小化损失函数也可以看作是最大化 margin 的过程,任何合格的分类损失函数都应该对 margin<0 的样本施以较大的惩罚。
其实,对于二分类问题,𝑦∈{−1,+1},损失函数常表示为关于𝑦𝑓(𝑥)的单调递减形式:(其实图像不仅仅是递减,而且这些损失函数都是0-1损失的进阶版——单调连续近似函数-最后面会提到)
10.介绍一下MTCNN网络,什么是P-Net、R-Net、O-Net?
附链接:https://www.cnblogs.com/yanshw/p/12418362.html;
https://blog.csdn.net/qq_36782182/article/details/83624357
这两篇作者讲的比较详细。
MTCNN,multi task convolutional neural network,多任务卷积神经网络;
它同时实现了人脸检测和关键点识别,关键点识别也叫人脸对齐;
检测和对齐是很多其他人脸应用的基础,如人脸识别,表情识别;
网络特点:
1. 级联网络
2. 在线困难样本选择 online hard sample dining
3. 速度非常快,可做实时检测
MTCNN 主体架构为 3 个逐级递进的级联网络,分别称为 P-Net、R-Net、O-Net,P-Net 快速生成粗略候选框,R-Net 进行过滤得到高精度候选框,O-Net 生成边界框和关键点坐标;
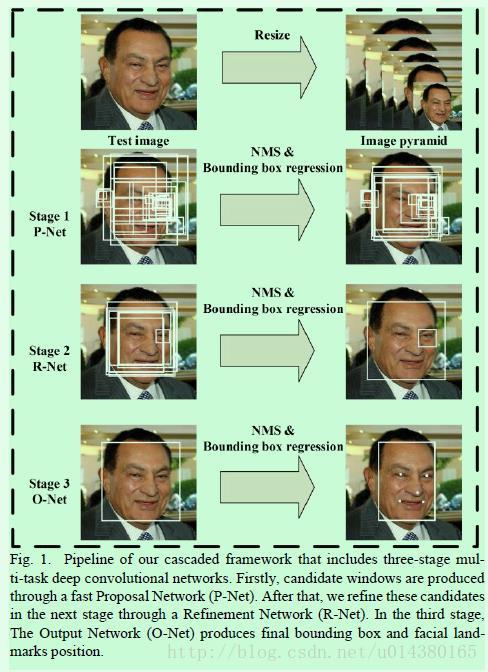
MTCNN 网络的形象理解:
三个级联网络,我们可以理解为面试过程,
HR 面试为 P-Net,HR 面试不能太严格,因为这样会漏掉很多合适的人选,故 P-Net 是一个简单的网络;
HR 面试完毕后,把通过的简历传给技术,技术面试为R-Net,技术面基本就能确定人选是否被录用,只是薪资可能无法确定,故 R-Net 基本就确定了是否为人脸,只是关键点没有指定;
技术面试完毕后,把通过的简历传给 boss,boss 面为终面,输出是否录用及薪资;
MTCNN实现流程:
1.构建图像金字塔
首先将图像进行不同尺度的变换,构建图像金字塔,以适应不同大小的人脸的进行检测。
2.P-Net
全称为Proposal Network,其基本的构造是一个全卷积网络。对上一步构建完成的图像金字塔,通过一个FCN进行初步特征提取与标定边框,并进行Bounding-Box Regression调整窗口与NMS进行大部分窗口的过滤。
P-Net是一个人脸区域的区域建议网络,该网络的将特征输入结果三个卷积层之后,通过一个人脸分类器判断该区域是否是人脸,同时使用边框回归和一个面部关键点的定位器来进行人脸区域的初步提议,该部分最终将输出很多张可能存在人脸的人脸区域,并将这些区域输入R-Net进行进一步处理。
这一部分的基本思想是使用较为浅层、较为简单的CNN快速生成人脸候选窗口。

3.R-Net
全称为Refine Network,其基本的构造是一个卷积神经网络,相对于第一层的P-Net来说,增加了一个全连接层,因此对于输入数据的筛选会更加严格。在图片经过P-Net后,会留下许多预测窗口,我们将所有的预测窗口送入R-Net,这个网络会滤除大量效果比较差的候选框,最后对选定的候选框进行Bounding-Box Regression和NMS进一步优化预测结果。
因为P-Net的输出只是具有一定可信度的可能的人脸区域,在这个网络中,将对输入进行细化选择,并且舍去大部分的错误输入,并再次使用边框回归和面部关键点定位器进行人脸区域的边框回归和关键点定位,最后将输出较为可信的人脸区域,供O-Net使用。对比与P-Net使用全卷积输出的1x1x32的特征,R-Net使用在最后一个卷积层之后使用了一个128的全连接层,保留了更多的图像特征,准确度性能也优于P-Net。
R-Net的思想是使用一个相对于P-Net更复杂的网络结构来对P-Net生成的可能是人脸区域区域窗口进行进一步选择和调整,从而达到高精度过滤和人脸区域优化的效果。

4.O-Net
全称为Output Network,基本结构是一个较为复杂的卷积神经网络,相对于R-Net来说多了一个卷积层。O-Net的效果与R-Net的区别在于这一层结构会通过更多的监督来识别面部的区域,而且会对人的面部特征点进行回归,最终输出五个人脸面部特征点。
是一个更复杂的卷积网络,该网络的输入特征更多,在网络结构的最后同样是一个更大的256的全连接层,保留了更多的图像特征,同时再进行人脸判别、人脸区域边框回归和人脸特征定位,最终输出人脸区域的左上角坐标和右下角坐标与人脸区域的五个特征点。O-Net拥有特征更多的输入和更复杂的网络结构,也具有更好的性能,这一层的输出作为最终的网络模型输出。
O-Net的思想和R-Net类似,使用更复杂的网络对模型性能进行优化

MTCNN 不仅可以做人脸检测,也可以做其他检测,如交通流检测,人流检测;
它与 Yolo 的区别在于,Yolo 是多目标检测,MTCNN 是多个单目标检测,MTCNN 在单目标检测领域要优于 Yolo;
11.FaceNet网络讲解一下。
与其他的深度学习方法在人脸上的应用不同,FaceNet并没有用传统的softmax的方式去进行分类学习,然后抽取其中某一层作为特征,而是直接进行端对端学习一个从图像到欧式空间的编码方法(Euclidean embedding),然后基于这个编码在嵌入空间(embedding space)用(欧氏距离)L2 distance对比做人脸识别、人脸验证和人脸聚类等。
12.线性变换和仿射变换的区别?
简单的来说,仿射变换就是:线性变换+ 平移。
线性变换三个要点:
- 变换前是直线,变换后依然是直线
- 直线比例保持不变
- 变换前是原点的,变换后依然是原点
仿射变换的两个要点:
- 变换前是直线的,变换后依然是直线
- 直线比例保持不变
- 变换前是原点的,变换后不是原点
13.有哪些调参经验?
附上链接:https://www.cnblogs.com/mfryf/p/11393648.html
UNIT1
case1:网络错误没有正确训练,损失完全不收敛。可能两种原因:1,错误的input data,网络无法学习。 2,错误的网络,网络无法学习。解决办法:(1)请检测自己的数据是否存在可以学习的信息,这个数据集中的数值是否泛化(防止过大或过小的数值破坏学习)。(2)如果是错误的数据则你需要去再次获得正确的数据,如果是数据的数值异常我们可以使用zscore函数来解决这个问题(3)如果是网络的错误,则希望调整网络,包括:网络深度,非线性程度,分类器的种类等等。
case2:部分收敛。可能原因:1.underfitting,就是网络的分类太简单了没办法去分类,因为没办法分类就是没办法学到正确的知识。2.overfitting,就是网络的分类太复杂了以至于它可以学习数据中的每一个信息甚至是错误的信息他都可以学习。解决办法:(1)underfitting: 增加网络的复杂度(深度),降低learning rate,优化数据集,增加网络的非线性度(ReLu),采用batch normalization。(2)overfitting: 丰富数据,增加网络的稀疏度,降低网络的复杂度(深度),L1 regularization,L2 regulariztion,添加Dropout,Early stopping,适当降低Learning rate,适当减少epoch的次数,
case3:全部收敛但效果不好。这是个好的开始,接下来我们要做的就是微调一些参数。解决办法:调整方法就是保持其他参数不变,只调整一个参数。这里需要调整的参数会有:learning rate,minibatch size,epoch,filter size,number of filter。
UNIT2
好的实验环境是成功的一半:(1)将各个参数的设置部分集中在一起。如果参数的设置分布在代码的各个地方,那么修改的过程想必会非常痛苦。(2)可以输出模型的损失函数值以及训练集和验证集上的准确率。(3)可以考虑设计一个子程序,可以根据给定的参数,启动训练并监控和周期性保存评估结果。再由一个主程序,分配参数以及并行启动一系列子程序。
画图:画图是一个很好的习惯,一般是训练数据遍历一轮以后,就输出一下训练集和验证集准确率。同时画到一张图上。这样训练一段时间以后,如果模型一直没有收敛,那么就可以停止训练,尝试其他参数了,以节省时间。 如果训练到最后,训练集,测试集准确率都很低,那么说明模型有可能欠拟合。那么后续调节参数方向,就是增强模型的拟合能力。例如增加网络层数,增加节点数,减少dropout值,减少L2正则值等等。 如果训练集准确率较高,测试集准确率比较低,那么模型有可能过拟合,这个时候就需要向提高模型泛化能力的方向,调节参数。
从粗到细分阶段调参:(1)建议先参考相关论文,以论文中给出的参数作为初始参数。至少论文中的参数,是个不差的结果。(2)如果找不到参考,那么只能自己尝试了。可以先从比较重要,对实验结果影响比较大的参数开始,同时固定其他参数,得到一个差不多的结果以后,在这个结果的基础上,再调其他参数。例如学习率一般就比正则值,dropout值重要的话,学习率设置的不合适,不仅结果可能变差,模型甚至会无法收敛。(3)如果实在找不到一组参数,可以让模型收敛。那么就需要检查,是不是其他地方出了问题,例如模型实现,数据等等。
提高速度:调参只是为了寻找合适的参数,而不是产出最终模型。一般在小数据集上合适的参数,在大数据集上效果也不会太差。因此可以尝试对数据进行精简,以提高速度,在有限的时间内可以尝试更多参数。(1)对训练数据进行采样。例如原来100W条数据,先采样成1W,进行实验看看。(2)减少训练类别。例如手写数字识别任务,原来是10个类别,那么我们可以先在2个类别上训练,看看结果如何。
超参数范围:建议优先在对数尺度上进行超参数搜索。比较典型的是学习率和正则化项,我们可以从诸如0.001 0.01 0.1 1 10,以10为阶数进行尝试。因为他们对训练的影响是相乘的效果。不过有些参数,还是建议在原始尺度上进行搜索,例如dropout值: 0.3 0.5 0.7)。
经验参数:
- learning rate: 1 0.1 0.01 0.001, 一般从1开始尝试。很少见learning rate大于10的。学习率一般要随着训练进行衰减。衰减系数一般是0.5。 衰减时机,可以是验证集准确率不再上升时,或固定训练多少个周期以后。 不过更建议使用自适应梯度的办法,例如adam,adadelta,rmsprop等,这些一般使用相关论文提供的默认值即可,可以避免再费劲调节学习率。对RNN来说,有个经验,如果RNN要处理的序列比较长,或者RNN层数比较多,那么learning rate一般小一些比较好,否则有可能出现结果不收敛,甚至Nan等问题。
- 网络层数: 先从1层开始。
- 每层结点数: 16 32 128,超过1000的情况比较少见。超过1W的从来没有见过。
- batch size: 128上下开始。batch size值增加,的确能提高训练速度。但是有可能收敛结果变差。如果显存大小允许,可以考虑从一个比较大的值开始尝试。因为batch size太大,一般不会对结果有太大的影响,而batch size太小的话,结果有可能很差。
- clip c(梯度裁剪): 限制最大梯度,其实是value = sqrt(w1^2+ w2^2….),如果value超过了阈值,就算一个衰减系系数,让value的值等于阈值: 5,10,15
- dropout: 0.5
- L2正则:1.0,超过10的很少见。
- 词向量embedding大小:128,256
- 正负样本比例: 这个是非常忽视,但是在很多分类问题上,又非常重要的参数。很多人往往习惯使用训练数据中默认的正负类别比例,当训练数据非常不平衡的时候,模型很有可能会偏向数目较大的类别,从而影响最终训练结果。除了尝试训练数据默认的正负类别比例之外,建议对数目较小的样本做过采样,例如进行复制。提高他们的比例,看看效果如何,这个对多分类问题同样适用。 在使用mini-batch方法进行训练的时候,尽量让一个batch内,各类别的比例平衡,这个在图像识别等多分类任务上非常重要。
自动调参:
- Gird Search. 这个是最常见的。具体说,就是每种参数确定好几个要尝试的值,然后像一个网格一样,把所有参数值的组合遍历一下。优点是实现简单暴力,如果能全部遍历的话,结果比较可靠。缺点是太费时间了,特别像神经网络,一般尝试不了太多的参数组合。
- Random Search。Bengio在Random Search for Hyper-Parameter Optimization中指出,Random Search比Gird Search更有效。实际操作的时候,一般也是先用Gird Search的方法,得到所有候选参数,然后每次从中随机选择进行训练。
- Bayesian Optimization. 贝叶斯优化,考虑到了不同参数对应的实验结果值,因此更节省时间。和网络搜索相比简直就是老牛和跑车的区别。具体原理可以参考这个论文: Practical Bayesian Optimization of Machine Learning Algorithms ,这里同时推荐两个实现了贝叶斯调参的Python库,可以上手即用:
- jaberg/hyperopt, 比较简单。
- fmfn/BayesianOptimization, 比较复杂,支持并行调参。
UNIT3
一些大的注意事项
- 刚开始, 先上小规模数据,模型往大了放,只要不爆显存,能用256个filter你就别用128个。直接奔着过拟合去。没错,就是训练过拟合网络, 连测试集验证集这些都可以不用。如果小数据量下,这么粗暴的大网络奔着过拟合去都没效果,那么有可能是:模型的输入输出是不是有问题? 代码错误? 模型解决的问题定义是不是有问题? 你对应用场景的理解是不是有错?
- Loss设计要合理。一般来说分类就是Softmax, 回归就是L2的loss. 但是要注意loss的错误范围(主要是回归), 你预测一个label是10000的值, 模型输出0, 你算算这loss多大, 这还是单变量的情况下. 一般结果都是nan. 所以不仅仅输入要做normalization, 输出也要这么弄。多任务情况下, 各loss想法限制在一个量级上, 或者最终限制在一个量级上, 初期可以着重一个任务的loss。
- 观察loss胜于观察准确率。准确率虽然是评测指标,但是训练过程中还是要注意loss的。你会发现有些情况下,准确率是突变的,原来一直是0, 可能保持上千迭代, 然后突然变1。要是因为这个你提前中断训练了, 只有老天替你惋惜了. 而loss是不会有这么诡异的情况发生的, 毕竟优化目标是loss。给NN一点时间, 要根据任务留给NN的学习一定空间. 不能说前面一段时间没起色就不管了. 有些情况下就是前面一段时间看不出起色, 然后开始稳定学习。
- 确认分类网络学习充分。分类网络就是学习类别之间的界限. 你会发现, 网络就是慢慢的从类别模糊到类别清晰的. 怎么发现? 看Softmax输出的概率的分布. 如果是二分类, 你会发现, 刚开始的网络预测都是在0.5上下, 很模糊. 随着学习过程, 网络预测会慢慢的移动到0,1这种极值附近. 所以, 如果你的网络预测分布靠中间, 再学习学习。
- Learning Rate设置合理。太大: loss爆炸, 或者nan。太小: 半天loss没反映。需要进一步降低了: loss在当前LR下一路降了下来, 但是半天不再降了。如果上面的Loss设计那块你没法合理, 初始情况下容易爆, 先上一个小LR保证不爆, 等loss降下来了, 再慢慢升LR, 之后当然还会慢慢再降LR。
- 对比训练集和验证集的loss。 判断过拟合, 训练是否足够, 是否需要early stop的依据。
- 清楚receptive field的大小。CV的任务, context window是很重要的. 所以你对自己模型的receptive field的大小要心中有数. 这个对效果的影响还是很显著的. 特别是用FCN, 大目标需要很大的receptive field。
简短的注意事项
- 预处理:-mean/std zero-center就够了, PCA, 白化什么的都用不上。
- shuffle, shuffle, shuffle(洗牌、打乱)。
- 网络原理的理解最重要,CNN的conv这块,你得明白sobel算子的边界检测。
- Dropout, Dropout, Dropout(不仅仅可以防止过拟合, 其实这相当于做人力成本最低的Ensemble, 当然, 训练起来会比没有Dropout的要慢一点, 同时网络参数你最好相应加一点, 对, 这会再慢一点)。
- CNN更加适合训练回答是否的问题, 如果任务比较复杂, 考虑先用分类任务训练一个模型再finetune。
- 无脑用ReLU(CV领域)。
- 无脑用3x3。
- 无脑用xavier。
- LRN一类的, 其实可以不用. 不行可以再拿来试试看。
- filter数量2^n
- 多尺度的图片输入(或者网络内部利用多尺度下的结果)有很好的提升效果。
- 第一层的filter, 数量不要太少. 否则根本学不出来(底层特征很重要)。
- sgd adam 这些选择上, 看你个人选择. 一般对网络不是决定性的. 反正我无脑用sgd + momentum。
- batch normalization我一直没用, 虽然我知道这个很好, 我不用仅仅是因为我懒. 所以要鼓励使用batch normalization。
- 不要完全相信论文里面的东西. 结构什么的觉得可能有效果, 可以拿去试试。
- 你有95%概率不会使用超过40层的模型。
- shortcut的联接是有作用的。
14.解释一下什么是IOU。
IOU 即交并比 即 Intersection-over-Union,是目标检测中使用的一个概念,是一种测量在特定数据集中检测相应物体准确度的一个标准。
IOU表示了产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率或者说重叠度,也就是它们的交集与并集的比值。相关度越高该值。最理想情况是完全重叠,即比值为1。

计算公式如下:
15.图像金字塔是什么?它的作用?
侦测的时候,将原图输入P_NET,可以得到(1, C, H, W)形状的特征图,特征图上的每个点的感受野为1212。1212的区域是很小的,无法预测原图上比较大的人脸,因此可以把原图进行缩放,传入P_NRT,原图上的人脸变小之后,P_NET才能准确预测人脸框。
图像金字塔是多分辨率图像处理中的一项重要技术 。它实质上是根据原始图像构建出来的一个图像序列;序列中的每个图像称为一个层, 它们尺寸递减并均为原始图像的一个低分辨率表示 ;金字塔的相邻层之间, 分辨率一般相差两倍。
16.人脸识别是侧脸的时候怎么检测?是否考虑过由距离确定人脸?
增侧脸加数据集,距离最近的并和数据库匹配的为目标人脸。
17.人脸识别项目用的是什么损失函数?介绍一下。
对于Tripletloss是深度学习中的一种损失函数,可以通过训练得到也可以使用已经训练好的Tripletloss。用于训练差异性较小的样本,如人脸等, 数据包括锚(Anchor)示例、正(Positive)示例、负(Negative)示例,通过优化锚示例与正示例的距离小于锚示例与负示例的距离,实现样本的相似性计算。
18.怎么改进FaceNet网络?或者用哪些更好的网络进行替换?
可以改变网络内部结构,比如使用: Inception-resnet-A、Inception-resnet-B、Inception-resnet-C;
三个模块其实都是Inception和resnet结合的变种残差网络。
它们在Inception-ResNetV1中会作为一个block被使用多次,例如5个连续的Inception-resnet-A放在一块使用,因为是残差网络,所以输入和输出是可以直接相加的。因此可以连续使用5个Inception-resnet-A;同理后面两个会被连续调用10次和5次。最后再经过一个全连接dense层,输出128的特征向量,这个特征向量是进行人脸识别的关键。因为相似的人脸它们的特征向量在欧式空间的距离是非常小的,我们就可以通过这个距离小于某个阈值来判断人脸。对得到的128的特征向量进行L2标准化,得到最终的特征向量。
19.为什么要进行图像预处理?有哪些方法?
- 图像的亮度、对比度等属性对图像的影响是非常大的,相同物体在不同的亮度,对比度下差别非常大。在图像识别的问题中,我们经常会遇到阴影、强曝光之类的图片,这些因素都不应该影响最后的识别结果,所以我们要对图像进行预处理,使得得到的神经网络模型尽可能小的被无关因素所影响。
- 在我们遇到图像样本过少,或者不均衡时,也可以使用图像预处理,增加样本数量。
- 有时物体拍摄的角度不同,也会有很大的差异,所以刻意将图像进行随机的翻转,可以提高模型健壮性
常见方法附链接:
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)